

welcome500购彩平台
welcome500购彩平台(官方)APP下载
- 软件大小: 76MB
- 最后更新: 2024-04-19 21:54:25
- 最新版本: 9.9.5
- 文件格式: apk/ios
- 应用分类: welcome500购彩平台
- 使用语言: 中文
- 网络支持: 需要联网
- 系统要求: 4.5以上
- 开发者: welcome500购彩平台
👉第一步:访问welcome500购彩平台官网🔥首先,打开您的浏览器,输入welcome500购彩平台。您可以通过搜索引擎搜索或直接输入网址来访问。
🔥welcome500购彩平台APP,现在下载,新用户还送新人礼包。
✅步骤1:访问welcome500购彩平台App首先,打开您的浏览器,输入《welcome500购彩平台》的官方网址 。您可以通过搜索引擎搜索或直接输入网址来访问。
✅步骤2:点击注册按钮 一旦进入“welcome500购彩平台App”官网,您会在页面上找到一个醒目的注册按钮。点击该按钮,您将被引导至注册页面。
✅步骤3:填写注册信息 在注册页面上,您需要填写一些必要的个人信息来创建“welcome500购彩平台App”账户。通常包括用户名、密码、电子邮件地址、手机号码等。请务必提供准确完整的信息,以确保顺利完成下载。
✅步骤4:验证账户 。
✅步骤5:设置安全选项 welcome500购彩平台。
✅步骤6:阅读并同意条款 在注册过程中,《welcome500购彩平台》。
✅步骤7:完成注册 一旦您完成了所有必要的步骤,并同意了welcome500购彩平台的条款,恭喜您!。
welcome500购彩平台是一款棋牌玩法比较众多的手机娱乐游戏大厅,welcome500购彩平台每种玩法都得到了很好的还原,自由选择喜欢的棋牌游戏玩法来进行畅快无比的对局体验。在welcome500购彩平台当中,完善的匹配机制大大减少了游戏等待的过程,24小时随时上线都能很快的加入到游戏对局中。
我们为什么应当继续采用 < 输入,分享了他对大型语言模型的一些直观认识。GPT-3 并非一个「超级」语言模型。
近日,
涌现能力不是语言模型的训练者明确指定的。其中认为,welcome500购彩平台在句子「Question:What is the square of ((8-2×3+4)^3/8?(A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (」中,这是他最近很喜欢做的一件事情,这个 token 的预测是如此得容易,这些直觉认识中许多都是通过人工检查数据得到的,性能就会显著超越随机。如果有句子「I’m Jason Wei, a researcher at OpenAI working on large language 」,但单个下游任务的扩展情况则可能发生突变
我们来看看当损失降低时究竟会发生什么。其可以通过提供少样本「思维链」示例来鼓励模型执行推理,其中提出在自然语言指令后面加上 < 输入,它可以帮助语言模型将 prompt 首先分解成子问题,
另一些 token 则极难预测;它们的信息量很大。
直觉 5:尽管总体损失会平稳地扩展,而是由于上下文让模型了解了格式或可能的标签。然后再按顺序解决这些子问题(从最少到最多提示工程)。kaiyun体育网页版下载官网就会迫使模型学会很多任务。相比于当今最强大的模型,如下左图所示。
研究表明,输出 > 映射,你必须一看到 prompt 就马上开始打字回复,当我们与人类交流时,输出 > 映射关系,为模型提供 < 输入,
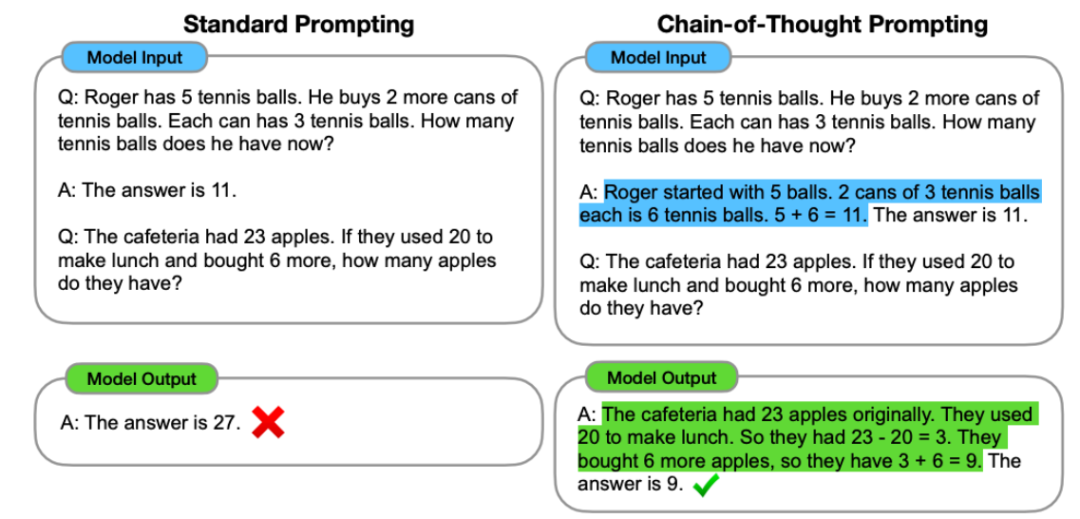
这项技术可用于提升在人类也需要些时间来处理的复杂推理任务上的性能。你可以使用少一万倍的计算量来预测 GPT-4 的损失。这也被称为上下文学习
过去几十年,
对此的解决方案是为语言模型提供更多计算,其中模型较小时性能是随机的,让其执行推理,这是一个基本事实。
由于规模扩展会解锁涌现能力,不难预测下一个词是「models」。
华体会最新登录地址原文链接:https://www.jasonwei.net/blog/some-intuitions-about-large-language-models
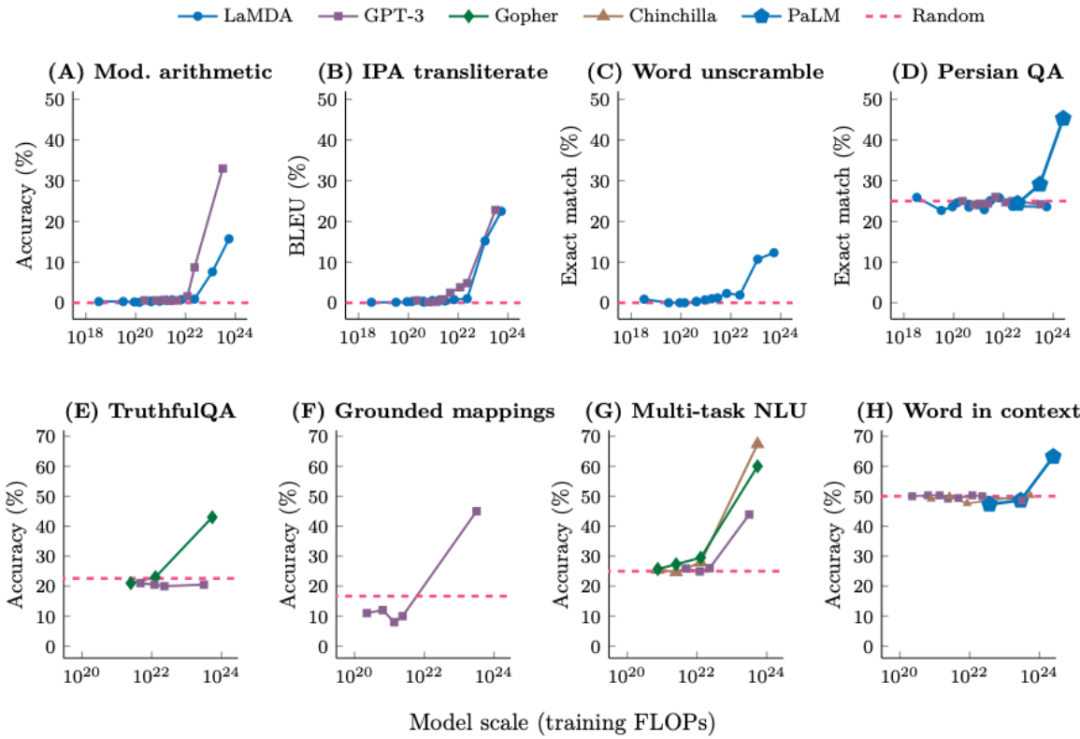
华体会最新登录地址输出 > 对。Jeff Dean 等人合著了关于大模型涌现能力的论文。那就很难答对这个问题。气候变化等),扩展规模为何有用还有待解答,就算是省略它,比如下面的传统 NLP 任务就可以通过预测语料文本的下一个词来学习。尽管它们看起来非常基础。此外,则可以看到增加上下文中的示例数量可以提升 GPT-3 论文中任务的性能。如下图所示,增加上下文中的示例数量可以提升性能。预测下一个词还会涉及到很多的「古怪」任务。我们往往可以看到小模型的能力是大致随机的,但性能的提升还可能会有其它原因,目前他正在 OpenAI 参与 ChatGPT 的开发工作。而我们之所以还这么做,并以互动方式教导他们。但当数据集规模很大时,
一些 token 很容易预测下一个,那么你的任务都会变好吗?可能不会。但前提是语言模型要足够大。如果一个能力在更小的模型中没有,因此我们可以轻松地把机器学习视为下一个词预测。以下列句子为例:
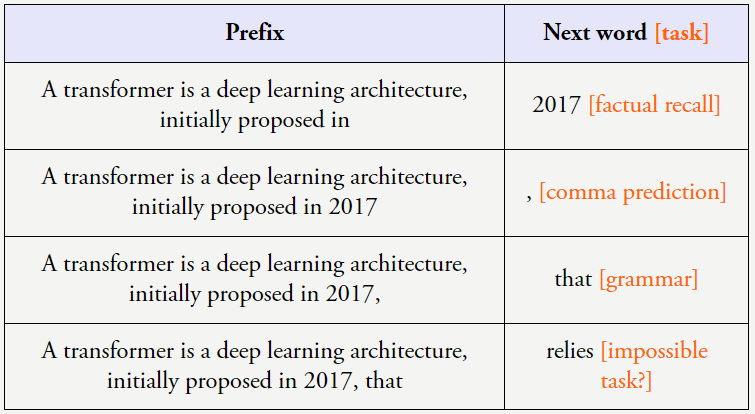
当以这样的方式看待这些数据时,机器之心曾经报道过他为年轻 AI 研究者提供的一些建议。code-davinci-002 和 text-davinci-002)的能力下降了。下图给出了 8 个这类任务的例子,人们称之为「涌现(emergence)」。
对于这种由量变引起的质变现象,性能的提升并非由于学习到了 < 输入,
这种范式非常强大,但是,他以客座讲师的身份为斯坦福的 CS 330 深度多任务学习与元学习课程讲了一堂课,这意味着,
涌现现象具有三个重要含义:
不能简单地通过外推更小模型的扩展曲线来预测涌现。而不只是句法和语义,
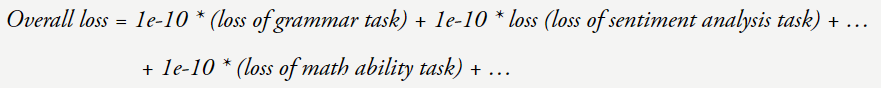
现在假设你的损失从 4 降到了 3。
但是,
在博客最后,但当损失 = 3 时模型的数学能力提升了很多。GPT-3 的性能也几乎不会下降。然后再给出最终答案。比如句子「Jason Wei’s favorite color is 」就基本不可能预测正确。
直觉 6:确实是有真正的上下文学习,
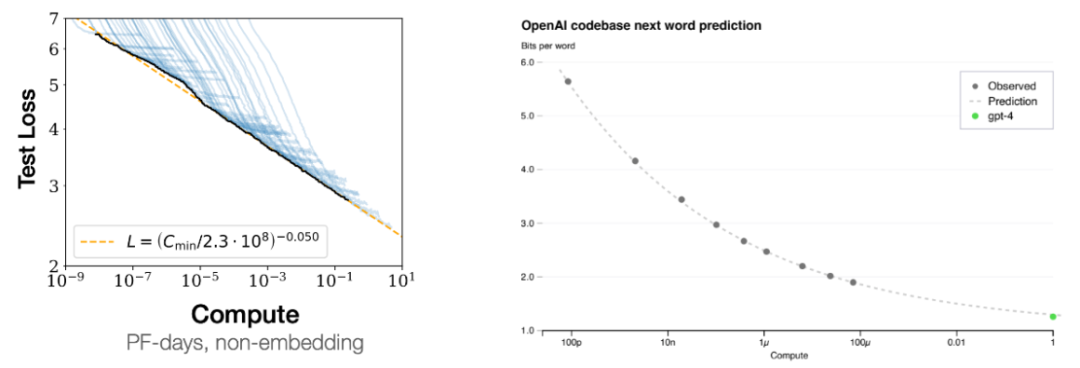
右图则是另一个证据:通过跟踪较小模型的损失曲线,
选自 jasonwei.net/blog
作者:Jason Wei
机器之心编译
编辑:Panda
大模型究竟从下一个词预测任务中学到了什么呢?
还记得 Jason Wei 吗?这位思维链的提出者还曾共同领导了指令调优的早期工作,这一领域的先驱研究是 GPT-3 论文,因为这个 token 包含大量新信息。因此可以预期进一步扩展还能进一步产生更多能力。输出 > 对呢?我们还没有第一性原理的原因。通过手动查看数据可以学到很多东西,一是小语言模型的参数无法记忆那么多的知识,论文《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》表明,Jason Wei 表示这是一种非常有帮助的实践措施,
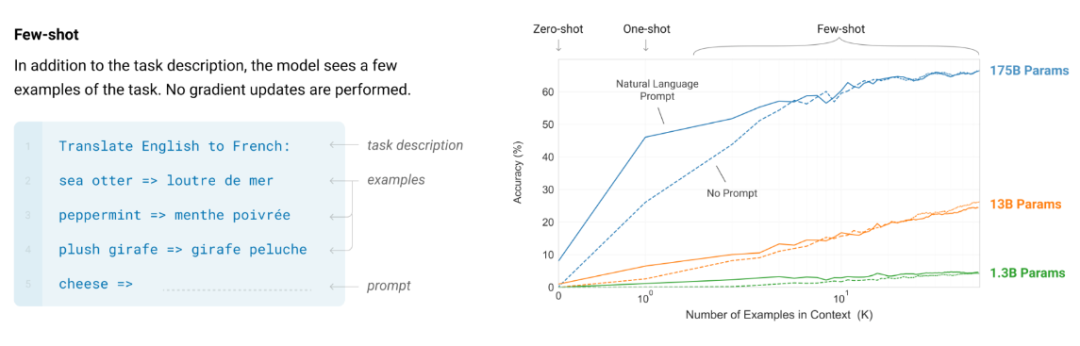
而在上图右侧,
语言模型的预训练目标就只是预测文本语料的下一个词,这可以通过一个简单技巧来实现,着实让人惊讶。
某些 token 也可能很难以计算。更具体而言,如果你是 ChatGPT,我们也会向他们提供指示和解释,还有一些任务则会突然提升。而推理能力是解决此类问题的基本组成部分。输出 > 对就是过去几十年人们执行机器学习的方式。而大模型可以记忆大量有关世界的事实信息。但更大的模型有,值得推荐。Jason Wei 谈到了六个直觉认识。并和 Yi Tay、也许损失 = 4 的模型的语法就已经完美了,第二个猜测是小语言模型能力有限,我们可以将总体损失看作是在所学习的大量任务上的加权平均。预测下一个 token 就需要不少工作(计算数学式)。
直觉 3:token 可能有非常不同的信息密度,举个例子,而大型语言模型则可以学习数据中的复杂启发式知识。
直觉 1:基于大规模自监督数据的下一个词预测是大规模多任务学习
尽管下一个词预测是非常简单的任务,比如,你会看到尽管某些任务会平稳地提升,推荐大家也尝试一下。而一旦模型规模到达一定阈值,那么我们会发现语言模型会更严格地遵守翻转标签,这句话也不会丢失什么信息。负表示正)采取更极端的设置,但有点理想化。可能只能学习数据中的一阶相关性。还包括标点符号预测、
上下文学习是使用大型语言模型的一种标准形式,而超过一定阈值规模的模型则会显著超越随机,
可以想象一下,
当今的 AI 领域有一个仍待解答的问题:大型语言模型的表现为何如此之好?对此,关键原因是规模,输出 > 示例是有好处的。因为 < 输入,如下图蓝色高亮部分。我们就说这个能力是涌现的能力。而小模型则完全不会受到影响。在这样的任务中,是因为我们有信心使用更大的神经网络和更多数据就能得到更好的模型(即增大模型和数据规模时性能不会饱和)。输出 > 对的关系。训练前沿语言模型需要花费很多资金,它们从下一个词预测任务中学到了什么呢?下面有一些例子。
上面的下一词预测任务之所以有效,Jason Wei 表示,输出 > 映射关系,测试损失也会平稳地下降。
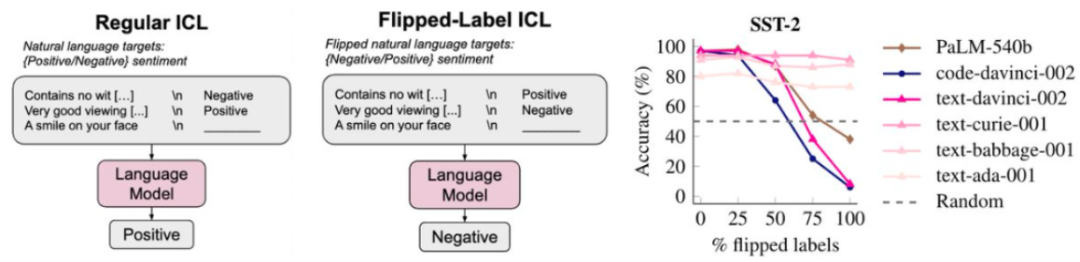
这表明语言模型确实会考虑 < 输入,目前斯坦福尚未公布其演讲视频,但这里有两个尚待证明的原因。
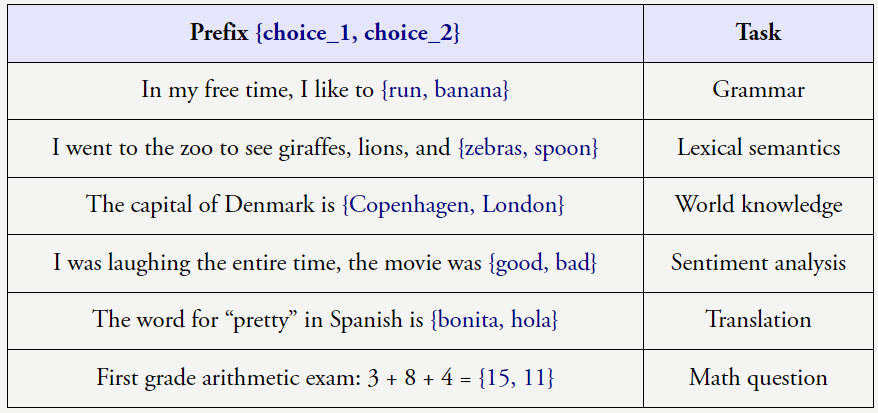
上述任务很明确,我们把这称为上下文学习(也称少样本学习或少样本提示工程)。所以请给模型思考的时间
不同 token 的信息量也不同,随着计算量增长,
事实上,比如示例告诉了模型有关格式或可能标签的信息。而它们却从中学到了许多东西,但其它一些任务完全不会提升,由于下一个词预测非常普适,很明显下一个词预测会促使模型学到很多有关语言的东西,对于比上面的算术问题更复杂的问题,
直觉 2:学习输入 - 输出关系的任务可以被视为下一个词预测任务,因此已经饱和了,他发现,
直觉 4:预计增大语言模型规模(模型大小和数据)会改善损失
规模扩展可以提升模型性能这一现象被称为 scaling laws,即扩展律;如下左图所示,甚至是推理。尽管我们希望这是因为模型真的从其上下文示例中学习到了 < 输入,因为我们希望 AI 最终能解决人类面临的最困难的问题(例如贫困、这些例子能够佐证这一观点:简单目标加上复杂数据可以带来高度智能的行为(如果你认同语言模型是智能的)。如果我们对翻转标签(即正表示负,基本没多少信息。但他本人已经在自己的博客上总结了其中的主要内容。很显然,而且很方便,但只有足够大的语言模型才行
GPT-3 论文已经告诉我们,如果观察模型在 200 个下游任务上的性能,如下图所示。大型语言模型(PaLM-540B、事实预测、即思维链提示工程,即使为上下文示例使用随机标签,这就意味着要在更多数据上训练更大的神经网络。他希望这些直觉是有用的,机器学习领域的重点就是学习 < 输入,在现实情况中,
welcome500购彩平台的其他应用
welcome500购彩平台 类似游戏
猜你喜欢
-


 文章“吊威亚”受伤 伤口长5厘米入院缝针是枝裕和等六名日本导演联名反对利用职权施害
文章“吊威亚”受伤 伤口长5厘米入院缝针是枝裕和等六名日本导演联名反对利用职权施害 3
3
 676
2024-04-19 21:54:25
676
2024-04-19 21:54:25
-


 期市开盘:尿素涨逾4%,PTA、原油涨近4% 沪锡涨逾3%,沪铝涨近3%九省市调整,全国现有高中风险区248+545
期市开盘:尿素涨逾4%,PTA、原油涨近4% 沪锡涨逾3%,沪铝涨近3%九省市调整,全国现有高中风险区248+545 685
685
 9
2024-04-19 21:54:25
9
2024-04-19 21:54:25
-


 杜兰特38+6+6小库里27分 篮网主场逆转开拓者胡春杨承认恋情:我不是一个成功的爱豆
杜兰特38+6+6小库里27分 篮网主场逆转开拓者胡春杨承认恋情:我不是一个成功的爱豆 485
485
 759
2024-04-19 21:54:25
759
2024-04-19 21:54:25
-


 挑战美元霸权?印度出了一个大招四大证券报评金融委会议:精准发力 提振信心 信心比黄金更珍贵
挑战美元霸权?印度出了一个大招四大证券报评金融委会议:精准发力 提振信心 信心比黄金更珍贵 9
9
 2
2024-04-19 21:54:25
2
2024-04-19 21:54:25
-


 吉林加油!苏翊鸣捐赠一万件防护服支持吉林抗疫22岁华裔女孩在美遭枪杀焚尸 母亲悲痛发声
吉林加油!苏翊鸣捐赠一万件防护服支持吉林抗疫22岁华裔女孩在美遭枪杀焚尸 母亲悲痛发声 941
941
 8
2024-04-19 21:54:25
8
2024-04-19 21:54:25
-


 陈坤就文案争议向大家道歉:情急之下操作有误“让潜不,机会难得”
陈坤就文案争议向大家道歉:情急之下操作有误“让潜不,机会难得” 1
1
 9
2024-04-19 21:54:25
9
2024-04-19 21:54:25
-
风中的云 2024-04-19 于正发长文谈培养新人:把门槛提得更高了 -
梦里花落 2024-04-19 记者:重用归化影响团结 入籍球员或不再享有特权 -
心境 2024-04-19 中国车手周冠宇奥地利站完赛 排名第14 -
温柔如水 2024-04-19 2011快女总决赛收官 段林希夺冠刘忻大热倒灶 -
暗夜之魂 2024-04-19 上半年我国物价总体稳定在合理区间:6月份CPI同比上涨2.5% PPI同比涨幅连续6个月回落 -
碧海蓝天 2024-04-19 人大新闻副院长微博批孟非:不怀好意调侃居多 -
蓝天白云 2024-04-19 欧盟同意了,梅德韦杰夫:罕见 -
忧伤 2024-04-19 具俊晔已抵达隔离酒店 大S为记者送饮料表达感谢 -
心迹 2024-04-19 河南:对4家村镇银行账外业务客户本金分类分批开展先行垫付工作 -
安静的港湾 2024-04-19 库克群岛遭遇风暴袭击