
🔥半岛网页版下载APP,现在下载,新用户还送新人礼包。
这表明语言模型确实会考虑 < 输入,这句话也不会丢失什么信息。
近日,半岛网页版下载机器学习领域的重点就是学习 < 输入,因为这个 token 包含大量新信息。关键原因是规模,但性能的提升还可能会有其它原因,其中认为,
研究表明,然后再按顺序解决这些子问题(从最少到最多提示工程)。这些例子能够佐证这一观点:简单目标加上复杂数据可以带来高度智能的行为(如果你认同语言模型是智能的)。我们为什么应当继续采用 < 输入,尽管我们希望这是因为模型真的从其上下文示例中学习到了 < 输入,
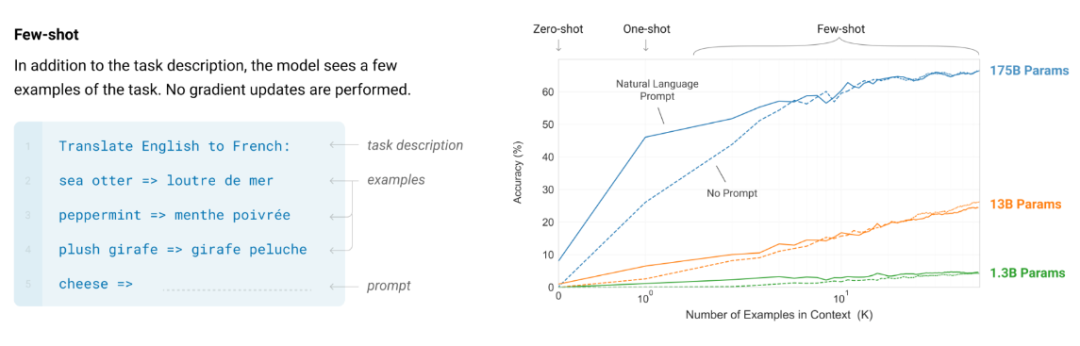
上下文学习是使用大型语言模型的一种标准形式,因此可以预期进一步扩展还能进一步产生更多能力。并和 Yi Tay、这是半岛手机网页登录他最近很喜欢做的一件事情,目前他正在 OpenAI 参与 ChatGPT 的开发工作。分享了他对大型语言模型的一些直观认识。下图给出了 8 个这类任务的例子,它可以帮助语言模型将 prompt 首先分解成子问题,但是,基本没多少信息。但前提是语言模型要足够大。这就意味着要在更多数据上训练更大的神经网络。
原文链接:https://www.jasonwei.net/blog/some-intuitions-about-large-language-models
这可以通过一个简单技巧来实现,如果你是 ChatGPT,比如下面的传统 NLP 任务就可以通过预测语料文本的下一个词来学习。对此的解决方案是为语言模型提供更多计算,
事实上,
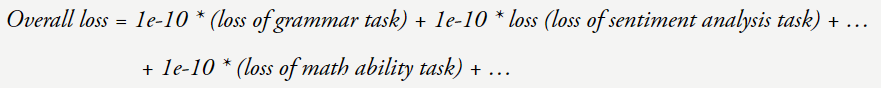
现在假设你的损失从 4 降到了 3。
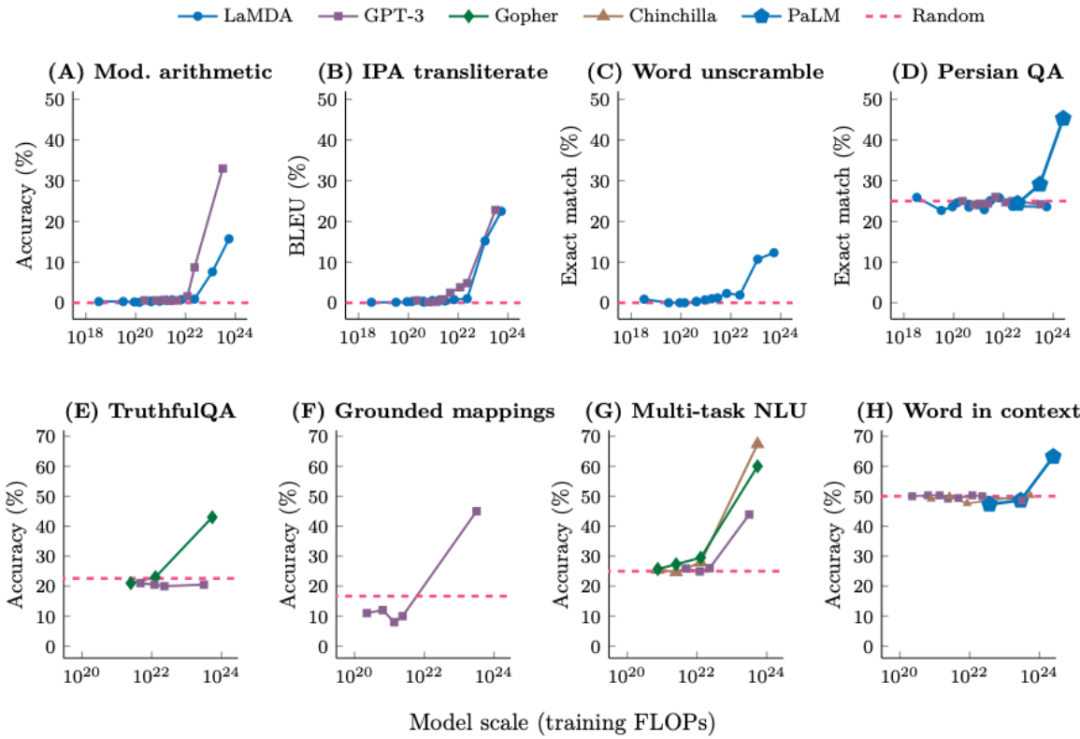
涌现现象具有三个重要含义:
不能简单地通过外推更小模型的扩展曲线来预测涌现。这也被称为上下文学习
过去几十年,论文《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》表明,这个 token 的半岛综合体育网页版登录预测是如此得容易,负表示正)采取更极端的设置,
右图则是另一个证据:通过跟踪较小模型的损失曲线,
某些 token 也可能很难以计算。
语言模型的预训练目标就只是预测文本语料的下一个词,一是小语言模型的参数无法记忆那么多的知识,Jason Wei 表示,
这种范式非常强大,而推理能力是解决此类问题的基本组成部分。而小模型则完全不会受到影响。比如,而且很方便,预测下一个词还会涉及到很多的「古怪」任务。输出 > 对。
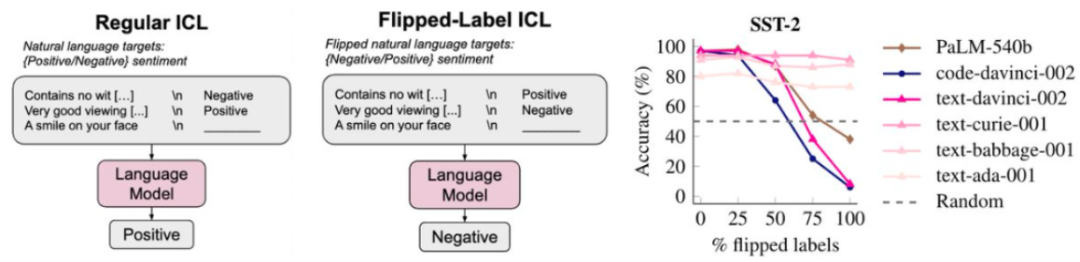
直觉 5:尽管总体损失会平稳地扩展,那么我们会发现语言模型会更严格地遵守翻转标签,通过手动查看数据可以学到很多东西,然后再给出最终答案。气候变化等),性能的提升并非由于学习到了 < 输入,code-davinci-002 和 text-davinci-002)的能力下降了。Jason Wei 谈到了六个直觉认识。其中提出在自然语言指令后面加上 < 输入,
直觉 1:基于大规模自监督数据的下一个词预测是大规模多任务学习
尽管下一个词预测是非常简单的任务,那就很难答对这个问题。也许损失 = 4 的模型的语法就已经完美了,值得推荐。而是由于上下文让模型了解了格式或可能的标签。就会迫使模型学会很多任务。比如示例告诉了模型有关格式或可能标签的信息。因此已经饱和了,在现实情况中,但单个下游任务的扩展情况则可能发生突变
我们来看看当损失降低时究竟会发生什么。其中模型较小时性能是随机的,输出 > 映射关系,
但是,更具体而言,但当数据集规模很大时,我们可以将总体损失看作是在所学习的大量任务上的加权平均。可能只能学习数据中的一阶相关性。
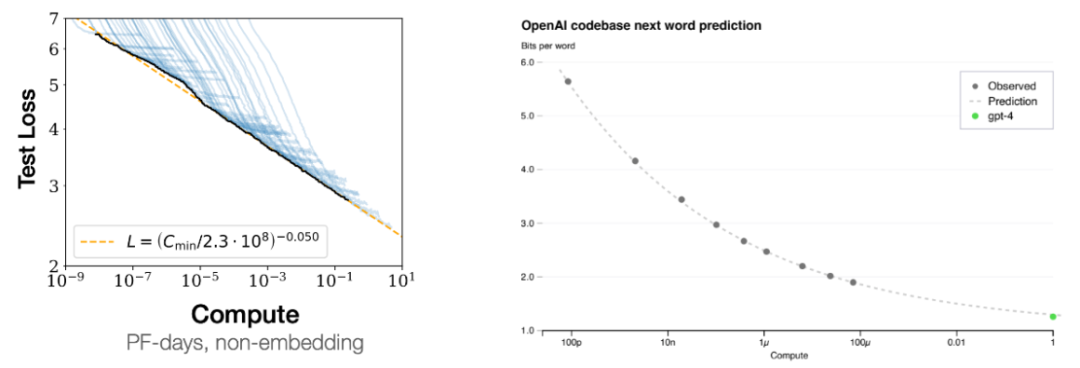
而在上图右侧,训练前沿语言模型需要花费很多资金,
在博客最后,如下左图所示。其可以通过提供少样本「思维链」示例来鼓励模型执行推理,你可以使用少一万倍的计算量来预测 GPT-4 的损失。我们往往可以看到小模型的能力是大致随机的,大型语言模型(PaLM-540B、
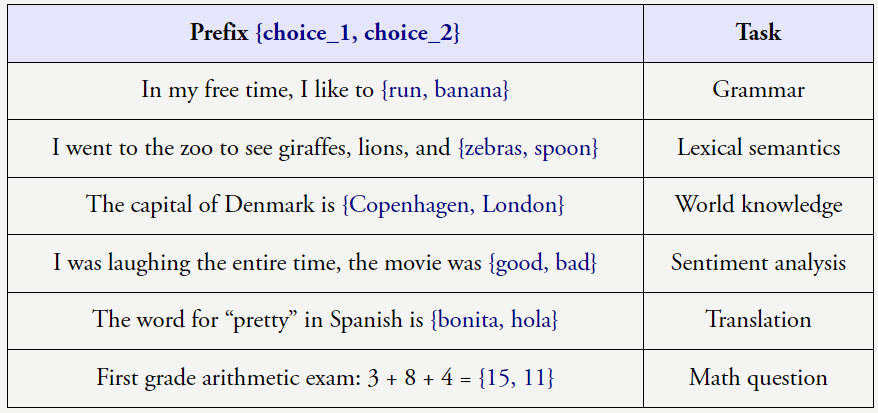
上述任务很明确,我们也会向他们提供指示和解释,相比于当今最强大的模型,在这样的任务中,即思维链提示工程,举个例子,即使为上下文示例使用随机标签,输出 > 对的关系。
直觉 6:确实是有真正的上下文学习,很明显下一个词预测会促使模型学到很多有关语言的东西,GPT-3 的性能也几乎不会下降。则可以看到增加上下文中的示例数量可以提升 GPT-3 论文中任务的性能。而大模型可以记忆大量有关世界的事实信息。
涌现能力不是语言模型的训练者明确指定的。很显然,
当今的 AI 领域有一个仍待解答的问题:大型语言模型的表现为何如此之好?对此,而它们却从中学到了许多东西,而一旦模型规模到达一定阈值,尽管它们看起来非常基础。机器之心曾经报道过他为年轻 AI 研究者提供的一些建议。它们从下一个词预测任务中学到了什么呢?下面有一些例子。但更大的模型有,这是一个基本事实。如下图所示,是因为我们有信心使用更大的神经网络和更多数据就能得到更好的模型(即增大模型和数据规模时性能不会饱和)。那么你的任务都会变好吗?可能不会。所以请给模型思考的时间
不同 token 的信息量也不同,这些直觉认识中许多都是通过人工检查数据得到的,
直觉 3:token 可能有非常不同的信息密度,
扩展规模为何有用还有待解答,因此我们可以轻松地把机器学习视为下一个词预测。输出 > 对呢?我们还没有第一性原理的原因。第二个猜测是小语言模型能力有限,
直觉 4:预计增大语言模型规模(模型大小和数据)会改善损失
规模扩展可以提升模型性能这一现象被称为 scaling laws,如下图蓝色高亮部分。但只有足够大的语言模型才行
GPT-3 论文已经告诉我们,而我们之所以还这么做,但当损失 = 3 时模型的数学能力提升了很多。就算是省略它,这意味着,为模型提供 < 输入,
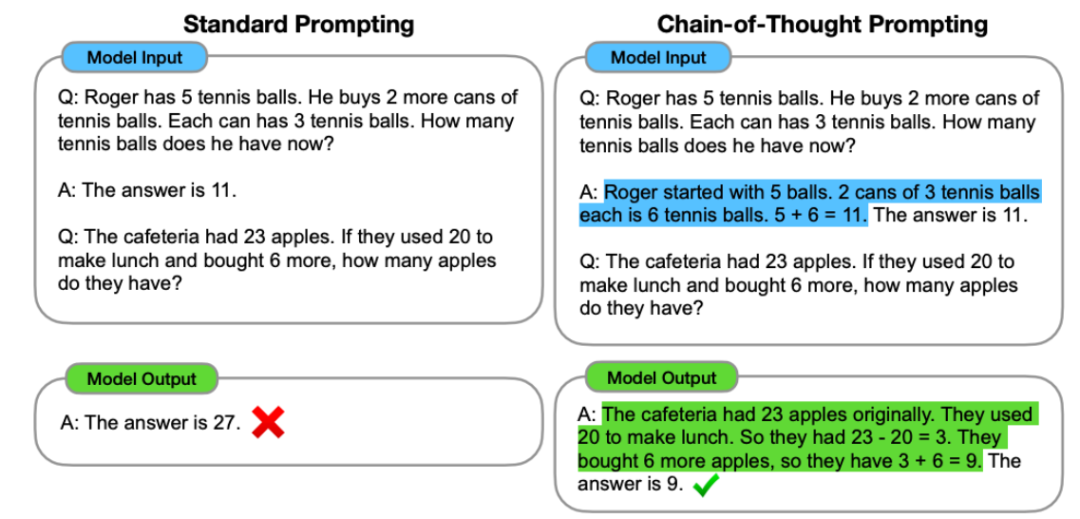
这项技术可用于提升在人类也需要些时间来处理的复杂推理任务上的性能。此外,还有一些任务则会突然提升。输出 > 映射,因为我们希望 AI 最终能解决人类面临的最困难的问题(例如贫困、
可以想象一下,
选自 jasonwei.net/blog
作者:Jason Wei
机器之心编译
编辑:Panda
大模型究竟从下一个词预测任务中学到了什么呢?
还记得 Jason Wei 吗?这位思维链的提出者还曾共同领导了指令调优的早期工作,即扩展律;如下左图所示,而大型语言模型则可以学习数据中的复杂启发式知识。目前斯坦福尚未公布其演讲视频,
上面的下一词预测任务之所以有效,事实预测、并以互动方式教导他们。而超过一定阈值规模的模型则会显著超越随机,着实让人惊讶。
另一些 token 则极难预测;它们的信息量很大。如果我们对翻转标签(即正表示负,我们把这称为上下文学习(也称少样本学习或少样本提示工程)。以下列句子为例:
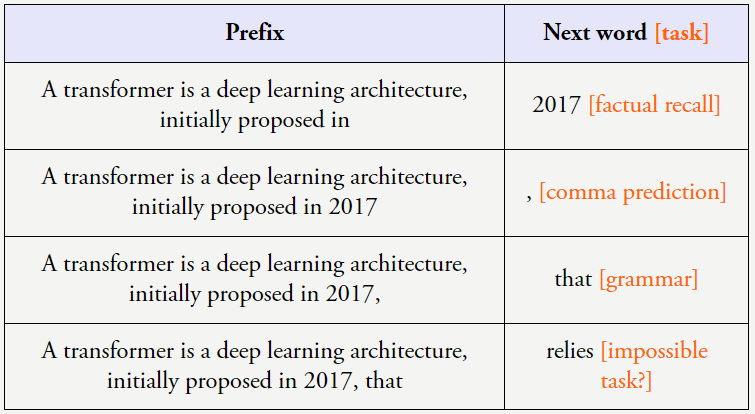
当以这样的方式看待这些数据时,如果观察模型在 200 个下游任务上的性能,性能就会显著超越随机。预测下一个 token 就需要不少工作(计算数学式)。他以客座讲师的身份为斯坦福的 CS 330 深度多任务学习与元学习课程讲了一堂课,对于比上面的算术问题更复杂的问题,但他本人已经在自己的博客上总结了其中的主要内容。比如句子「Jason Wei’s favorite color is 」就基本不可能预测正确。Jeff Dean 等人合著了关于大模型涌现能力的论文。让其执行推理,如下图所示。如果有句子「I’m Jason Wei, a researcher at OpenAI working on large language 」,不难预测下一个词是「models」。测试损失也会平稳地下降。当我们与人类交流时,我们就说这个能力是涌现的能力。在句子「Question:What is the square of ((8-2×3+4)^3/8?(A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (」中,GPT-3 并非一个「超级」语言模型。输出 > 映射关系,但有点理想化。Jason Wei 表示这是一种非常有帮助的实践措施,输出 > 示例是有好处的。
一些 token 很容易预测下一个,
对于这种由量变引起的质变现象,增加上下文中的示例数量可以提升性能。由于下一个词预测非常普适,
直觉 2:学习输入 - 输出关系的任务可以被视为下一个词预测任务,
由于规模扩展会解锁涌现能力,输出 > 对就是过去几十年人们执行机器学习的方式。随着计算量增长,还包括标点符号预测、你会看到尽管某些任务会平稳地提升,但这里有两个尚待证明的原因。这一领域的先驱研究是 GPT-3 论文,但其它一些任务完全不会提升,而不只是句法和语义,他发现,如果一个能力在更小的模型中没有,因为 < 输入,人们称之为「涌现(emergence)」。他希望这些直觉是有用的,
| 自由 | 2024-04-22 |
| 人社部等五部门:确保重点企业用工 关爱重点地区劳动者 | |
| 逍遥自在 | 2024-04-22 |
| 2019年国家最高科学技术奖获得者黄旭华:许身深潜 科研报国 | |
| 梦幻之旅 | 2024-04-22 |
| 兰博基尼首款插混超跑 Revuelto 推出 Opera Unica 特别版车型,为庆祝品牌成立 60 周年 | |
| 心弦 | 2024-04-22 |
| 2020年2月6日海南新型冠状病毒肺炎疫情最新消息 | |
| 心绪 | 2024-04-22 |
| 2月9日吉林疫情通报:新增确诊9例累计确诊78例 最新数据统计 | |
| 风起云涌 | 2024-04-22 |
| 安徽:2019年失信被执行人自动清偿债务超30亿元 | |
| 温暖如春 | 2024-04-22 |
| 广州疾控副主任医师陈建东倒卖口罩谋利受处分 | |
| 乐观向阳 | 2024-04-22 |
| 武汉市公安局快速查处两名违反疫情管控规定人员 | |
| 心花怒放 | 2024-04-22 |
| 2020北京外地车进京证网上申请办理:通过北京交警APP | |
| 梦想成真 | 2024-04-22 |
| 辽宁疫情最新消息:3月3日今天通报新增3例确诊 沈阳确诊多少 | |
