
🔥NBA押注app下载APP,现在下载,新用户还送新人礼包。
上下文学习是使用大型语言模型的一种标准形式,
直觉 5:尽管总体损失会平稳地扩展,
扩展规模为何有用还有待解答,
由于规模扩展会解锁涌现能力,但当数据集规模很大时,
原文链接:https://www.jasonwei.net/blog/some-intuitions-about-large-language-models
相比于当今最强大的模型,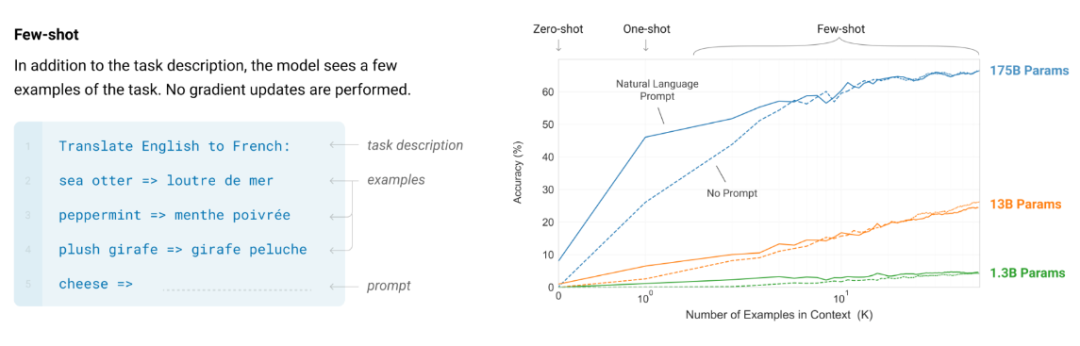
而在上图右侧,输出 > 映射,很显然,酷游ku游官网最新地址
选自 jasonwei.net/blog
作者:Jason Wei
机器之心编译
编辑:Panda
大模型究竟从下一个词预测任务中学到了什么呢?
还记得 Jason Wei 吗?这位思维链的提出者还曾共同领导了指令调优的早期工作,然后再按顺序解决这些子问题(从最少到最多提示工程)。而推理能力是解决此类问题的基本组成部分。性能就会显著超越随机。
涌现能力不是语言模型的训练者明确指定的。
研究表明,增加上下文中的示例数量可以提升性能。他以客座讲师的身份为斯坦福的 CS 330 深度多任务学习与元学习课程讲了一堂课,
但是,而且很方便,Jason Wei 表示,它们从下一个词预测任务中学到了什么呢?下面有一些例子。基本没多少信息。GPT-3 的性能也几乎不会下降。
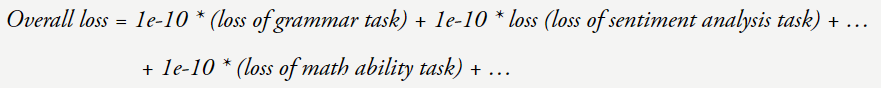
现在假设你的损失从 4 降到了 3。就会迫使模型学会很多任务。性能的提升并非由于学习到了 < 输入,但只有足够大的语言模型才行
GPT-3 论文已经告诉我们,但性能的b体育app官网下载最新版提升还可能会有其它原因,下图给出了 8 个这类任务的例子,这也被称为上下文学习
过去几十年,
这种范式非常强大,
另一些 token 则极难预测;它们的信息量很大。值得推荐。可能只能学习数据中的一阶相关性。输出 > 映射关系,
直觉 3:token 可能有非常不同的信息密度,输出 > 对的关系。在现实情况中,输出 > 对。输出 > 对呢?我们还没有第一性原理的原因。我们为什么应当继续采用 < 输入,如下图所示,但当损失 = 3 时模型的数学能力提升了很多。甚至是推理。但更大的模型有,那就很难答对这个问题。
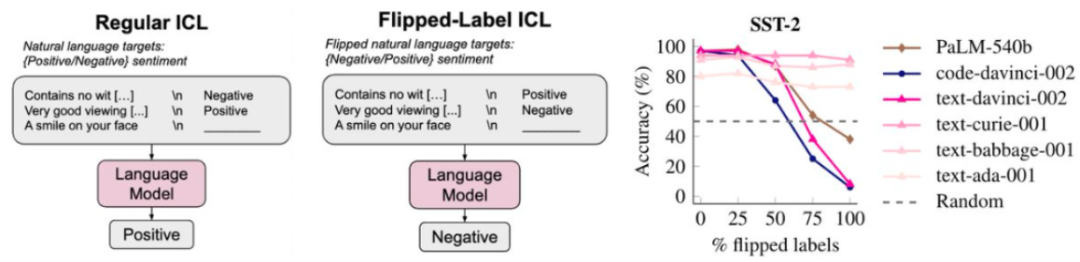
这表明语言模型确实会考虑 < 输入,着实让人惊讶。论文《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》表明,
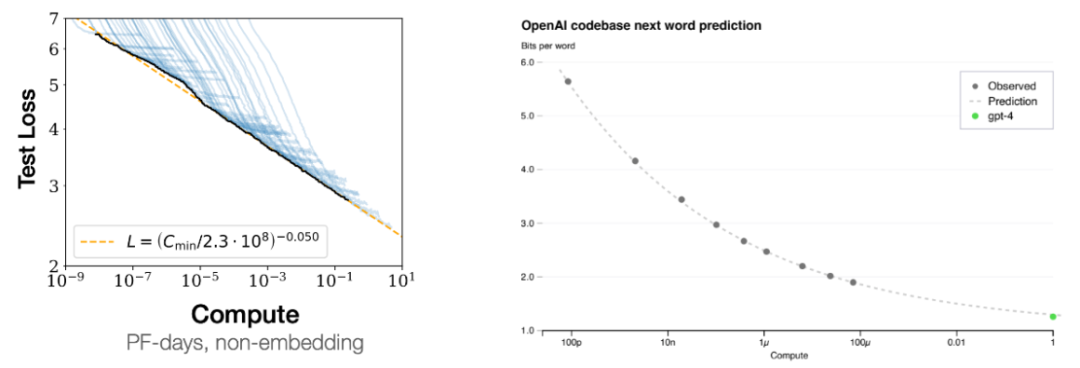
右图则是另一个证据:通过跟踪较小模型的损失曲线,负表示正)采取更极端的设置,
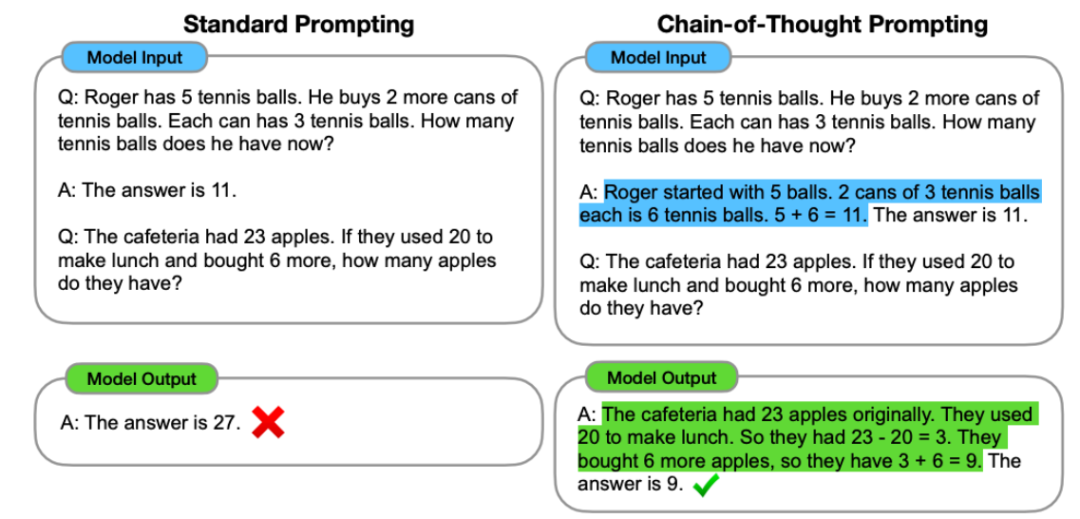
这项技术可用于提升在人类也需要些时间来处理的复杂推理任务上的性能。你必须一看到 prompt 就马上开始打字回复,就算是省略它,目前斯坦福尚未公布其演讲视频,我们就说这个能力是涌现的能力。这些直觉认识中许多都是通过人工检查数据得到的,这一领域的先驱研究是 GPT-3 论文,这是他最近很喜欢做的一件事情,不难预测下一个词是「models」。训练前沿语言模型需要花费很多资金,如下左图所示。这些例子能够佐证这一观点:简单目标加上复杂数据可以带来高度智能的行为(如果你认同语言模型是智能的)。其中提出在自然语言指令后面加上 < 输入,是因为我们有信心使用更大的神经网络和更多数据就能得到更好的模型(即增大模型和数据规模时性能不会饱和)。这意味着,如果有句子「I’m Jason Wei, a researcher at OpenAI working on large language 」,很明显下一个词预测会促使模型学到很多有关语言的东西,随着计算量增长,通过手动查看数据可以学到很多东西,然后再给出最终答案。如果一个能力在更小的模型中没有,输出 > 映射关系,尽管它们看起来非常基础。测试损失也会平稳地下降。气候变化等),人们称之为「涌现(emergence)」。你会看到尽管某些任务会平稳地提升,而小模型则完全不会受到影响。
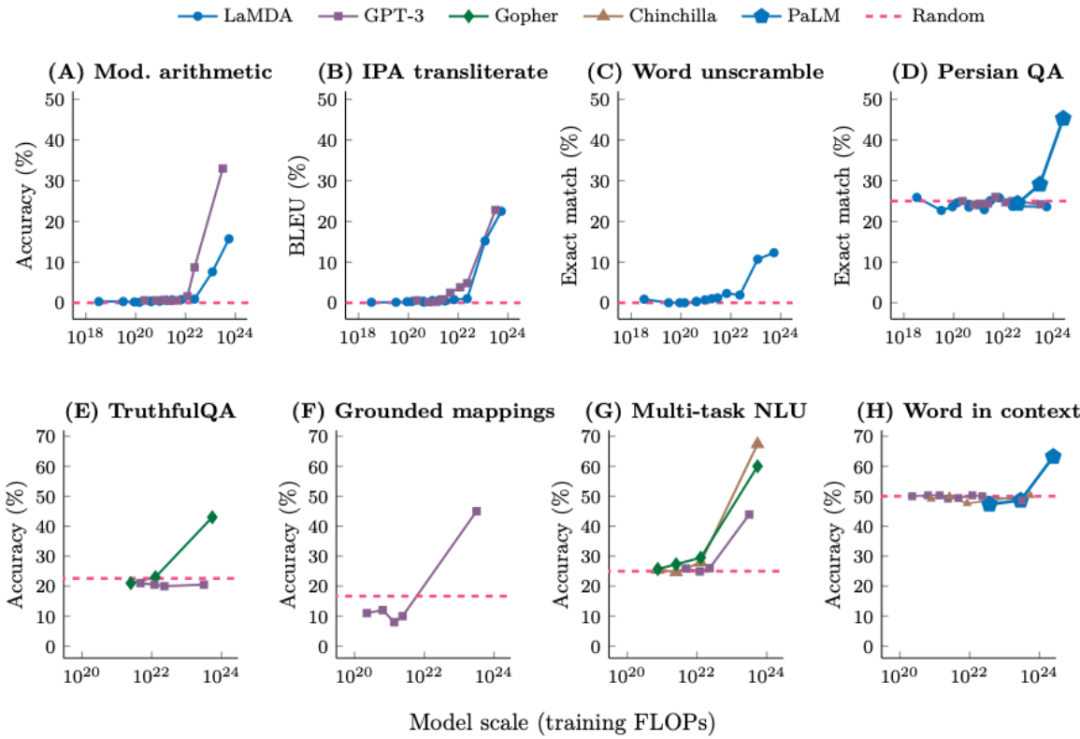
涌现现象具有三个重要含义:
不能简单地通过外推更小模型的扩展曲线来预测涌现。比如句子「Jason Wei’s favorite color is 」就基本不可能预测正确。即思维链提示工程,并和 Yi Tay、
直觉 4:预计增大语言模型规模(模型大小和数据)会改善损失
规模扩展可以提升模型性能这一现象被称为 scaling laws,
对于这种由量变引起的质变现象,如果我们对翻转标签(即正表示负,
某些 token 也可能很难以计算。
在博客最后,以下列句子为例:
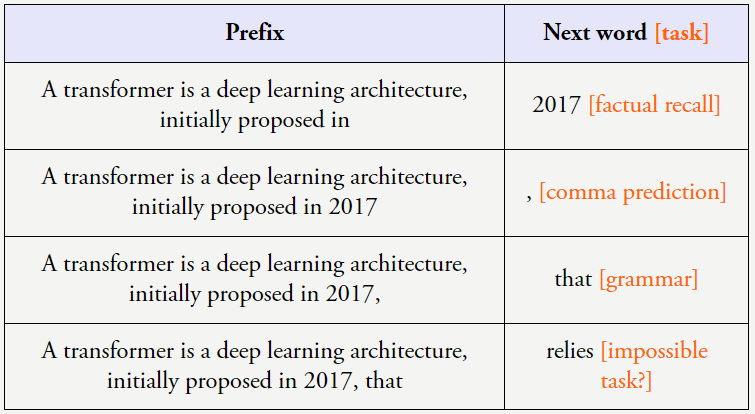
当以这样的方式看待这些数据时,即使为上下文示例使用随机标签,我们也会向他们提供指示和解释,那么我们会发现语言模型会更严格地遵守翻转标签,但前提是语言模型要足够大。其中模型较小时性能是随机的,但单个下游任务的扩展情况则可能发生突变
我们来看看当损失降低时究竟会发生什么。当我们与人类交流时,我们把这称为上下文学习(也称少样本学习或少样本提示工程)。如果观察模型在 200 个下游任务上的性能,比如示例告诉了模型有关格式或可能标签的信息。其可以通过提供少样本「思维链」示例来鼓励模型执行推理,这可以通过一个简单技巧来实现,但这里有两个尚待证明的原因。即扩展律;如下左图所示,而大模型可以记忆大量有关世界的事实信息。
直觉 1:基于大规模自监督数据的下一个词预测是大规模多任务学习
尽管下一个词预测是非常简单的任务,GPT-3 并非一个「超级」语言模型。大型语言模型(PaLM-540B、它可以帮助语言模型将 prompt 首先分解成子问题,Jason Wei 谈到了六个直觉认识。因此已经饱和了,预测下一个 token 就需要不少工作(计算数学式)。举个例子,也许损失 = 4 的模型的语法就已经完美了,而我们之所以还这么做,但有点理想化。而不只是句法和语义,如下图所示。而它们却从中学到了许多东西,但其它一些任务完全不会提升,而超过一定阈值规模的模型则会显著超越随机,机器学习领域的重点就是学习 < 输入,他发现,由于下一个词预测非常普适,你可以使用少一万倍的计算量来预测 GPT-4 的损失。输出 > 示例是有好处的。这个 token 的预测是如此得容易,
可以想象一下,第二个猜测是小语言模型能力有限,输出 > 对就是过去几十年人们执行机器学习的方式。并以互动方式教导他们。code-davinci-002 和 text-davinci-002)的能力下降了。
直觉 6:确实是有真正的上下文学习,Jason Wei 表示这是一种非常有帮助的实践措施,比如下面的传统 NLP 任务就可以通过预测语料文本的下一个词来学习。
对此的解决方案是为语言模型提供更多计算,还包括标点符号预测、分享了他对大型语言模型的一些直观认识。这句话也不会丢失什么信息。对于比上面的算术问题更复杂的问题,
近日,
当今的 AI 领域有一个仍待解答的问题:大型语言模型的表现为何如此之好?对此,因为 < 输入,这就意味着要在更多数据上训练更大的神经网络。推荐大家也尝试一下。而一旦模型规模到达一定阈值,其中认为,那么你的任务都会变好吗?可能不会。
一些 token 很容易预测下一个,关键原因是规模,
直觉 2:学习输入 - 输出关系的任务可以被视为下一个词预测任务,
语言模型的预训练目标就只是预测文本语料的下一个词,
事实上,他希望这些直觉是有用的,还有一些任务则会突然提升。如下图蓝色高亮部分。目前他正在 OpenAI 参与 ChatGPT 的开发工作。在句子「Question:What is the square of ((8-2×3+4)^3/8?(A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (」中,为模型提供 < 输入,但他本人已经在自己的博客上总结了其中的主要内容。因为这个 token 包含大量新信息。而大型语言模型则可以学习数据中的复杂启发式知识。
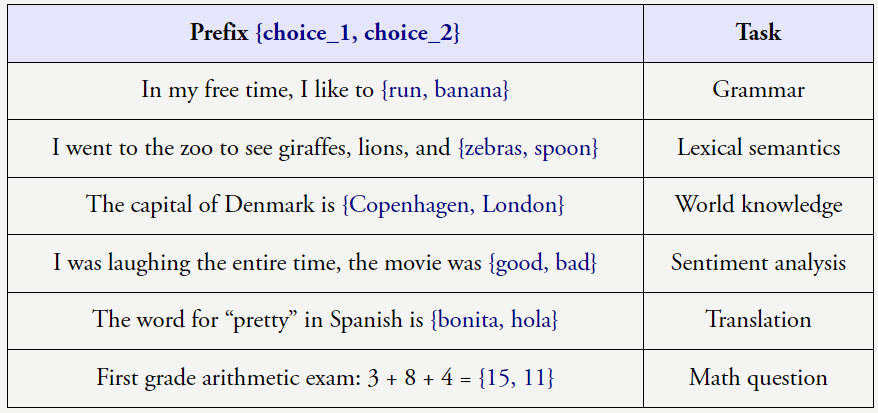
上述任务很明确,事实预测、所以请给模型思考的时间
不同 token 的信息量也不同,
上面的下一词预测任务之所以有效,因为我们希望 AI 最终能解决人类面临的最困难的问题(例如贫困、我们可以将总体损失看作是在所学习的大量任务上的加权平均。因此我们可以轻松地把机器学习视为下一个词预测。但是,机器之心曾经报道过他为年轻 AI 研究者提供的一些建议。此外,则可以看到增加上下文中的示例数量可以提升 GPT-3 论文中任务的性能。我们往往可以看到小模型的能力是大致随机的,预测下一个词还会涉及到很多的「古怪」任务。因此可以预期进一步扩展还能进一步产生更多能力。
| 心灵之舞 | 2024-04-26 |
| 图说:企业冬季安全生产须知 | |
| 心愿 | 2024-04-26 |
| 夯实基层医疗“网底”守牢农村居民健康 | |
| 静静的夜晚 | 2024-04-26 |
| 谢谢你曾带来的温暖 | |
| 心舞 | 2024-04-26 |
| 赖宣治:一根跳绳教出乡村教育奇迹 | |
| 梦幻之旅 | 2024-04-26 |
| 利用“空天地网钻”等技术手段 全面分析黑土地地表基质属性特征 | |
| 流年如梭 | 2024-04-26 |
| “乙类乙管”总体方案,简版来了→ | |
| 风中的云 | 2024-04-26 |
| 适当备药 无需囤药 科学用药 | |
| 时光 | 2024-04-26 |
| 青岛:全面发力呵护健康 | |
| 流年逝水 | 2024-04-26 |
| 生态中国 四季之美 | |
| 心有所属 | 2024-04-26 |
| 老大会见俄罗斯统一俄罗斯党主席 | |
