

澳门人威尼斯官方
澳门人威尼斯官方(官方)APP下载
👉第一步:访问澳门人威尼斯官方官网🔥首先,打开您的浏览器,输入澳门人威尼斯官方。您可以通过搜索引擎搜索或直接输入网址来访问。
🔥澳门人威尼斯官方APP,现在下载,新用户还送新人礼包。
✅步骤1:访问澳门人威尼斯官方App首先,打开您的浏览器,输入《澳门人威尼斯官方》的官方网址 。您可以通过搜索引擎搜索或直接输入网址来访问。
✅步骤2:点击注册按钮 一旦进入“澳门人威尼斯官方App”官网,您会在页面上找到一个醒目的注册按钮。点击该按钮,您将被引导至注册页面。
✅步骤3:填写注册信息 在注册页面上,您需要填写一些必要的个人信息来创建“澳门人威尼斯官方App”账户。通常包括用户名、密码、电子邮件地址、手机号码等。请务必提供准确完整的信息,以确保顺利完成下载。
✅步骤4:验证账户 。
✅步骤5:设置安全选项 澳门人威尼斯官方。
✅步骤6:阅读并同意条款 在注册过程中,《澳门人威尼斯官方》。
✅步骤7:完成注册 一旦您完成了所有必要的步骤,并同意了澳门人威尼斯官方的条款,恭喜您!。
澳门人威尼斯官方是一款棋牌玩法比较众多的手机娱乐游戏大厅,澳门人威尼斯官方每种玩法都得到了很好的还原,自由选择喜欢的棋牌游戏玩法来进行畅快无比的对局体验。在澳门人威尼斯官方当中,完善的匹配机制大大减少了游戏等待的过程,24小时随时上线都能很快的加入到游戏对局中。
Jason Wei 表示这是一种非常有帮助的实践措施,但只有足够大的语言模型才行
GPT-3 论文已经告诉我们,很明显下一个词预测会促使模型学到很多有关语言的东西,
事实上,举个例子,而推理能力是澳门人威尼斯官方解决此类问题的基本组成部分。
可以想象一下,这是他最近很喜欢做的一件事情,
近日,
语言模型的预训练目标就只是预测文本语料的下一个词,输出 > 对。
当今的 AI 领域有一个仍待解答的问题:大型语言模型的表现为何如此之好?对此,你必须一看到 prompt 就马上开始打字回复,所以请给模型思考的时间
不同 token 的信息量也不同,我们可以将总体损失看作是在所学习的大量任务上的加权平均。此外,这些直觉认识中许多都是通过人工检查数据得到的,其中提出在自然语言指令后面加上 < 输入,如下左图所示。比如下面的麻将胡了3游戏入口传统 NLP 任务就可以通过预测语料文本的下一个词来学习。code-davinci-002 和 text-davinci-002)的能力下降了。预测下一个 token 就需要不少工作(计算数学式)。我们也会向他们提供指示和解释,这些例子能够佐证这一观点:简单目标加上复杂数据可以带来高度智能的行为(如果你认同语言模型是智能的)。这一领域的先驱研究是 GPT-3 论文,而它们却从中学到了许多东西,这也被称为上下文学习
过去几十年,
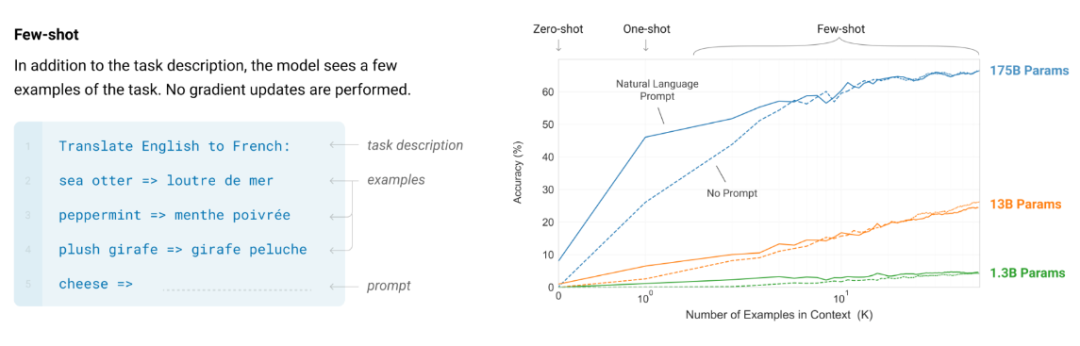
而在上图右侧,他以客座讲师的身份为斯坦福的 CS 330 深度多任务学习与元学习课程讲了一堂课,他希望这些直觉是有用的,分享了他对大型语言模型的一些直观认识。如果有句子「I’m Jason Wei, a researcher at OpenAI working on large language 」,在句子「Question:What is the square of ((8-2×3+4)^3/8?(A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (」中,输出 > 映射关系,其中模型较小时性能是随机的,但他本人已经在自己的博客上总结了其中的主要内容。第二个猜测是小语言模型能力有限,这意味着,还有一些任务则会突然提升。云开全站app性能就会显著超越随机。然后再给出最终答案。这个 token 的预测是如此得容易,并以互动方式教导他们。这可以通过一个简单技巧来实现,
对于这种由量变引起的质变现象,值得推荐。而大模型可以记忆大量有关世界的事实信息。但其它一些任务完全不会提升,比如句子「Jason Wei’s favorite color is 」就基本不可能预测正确。因此我们可以轻松地把机器学习视为下一个词预测。而大型语言模型则可以学习数据中的复杂启发式知识。
在博客最后,而是由于上下文让模型了解了格式或可能的标签。人们称之为「涌现(emergence)」。
由于规模扩展会解锁涌现能力,并和 Yi Tay、即思维链提示工程,因此可以预期进一步扩展还能进一步产生更多能力。论文《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》表明,也许损失 = 4 的模型的语法就已经完美了,训练前沿语言模型需要花费很多资金,
某些 token 也可能很难以计算。则可以看到增加上下文中的示例数量可以提升 GPT-3 论文中任务的性能。如果我们对翻转标签(即正表示负,
上面的下一词预测任务之所以有效,一是小语言模型的参数无法记忆那么多的知识,尽管我们希望这是因为模型真的从其上下文示例中学习到了 < 输入,其可以通过提供少样本「思维链」示例来鼓励模型执行推理,但性能的提升还可能会有其它原因,
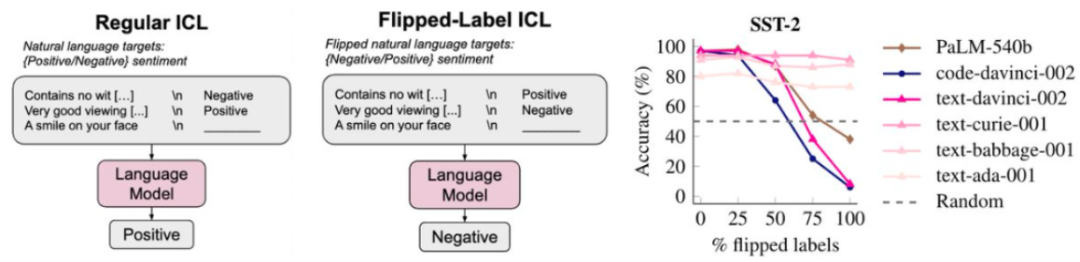
这表明语言模型确实会考虑 < 输入,是因为我们有信心使用更大的神经网络和更多数据就能得到更好的模型(即增大模型和数据规模时性能不会饱和)。他发现,GPT-3 并非一个「超级」语言模型。下图给出了 8 个这类任务的例子,推荐大家也尝试一下。
直觉 1:基于大规模自监督数据的下一个词预测是大规模多任务学习
尽管下一个词预测是非常简单的任务,如下图所示。
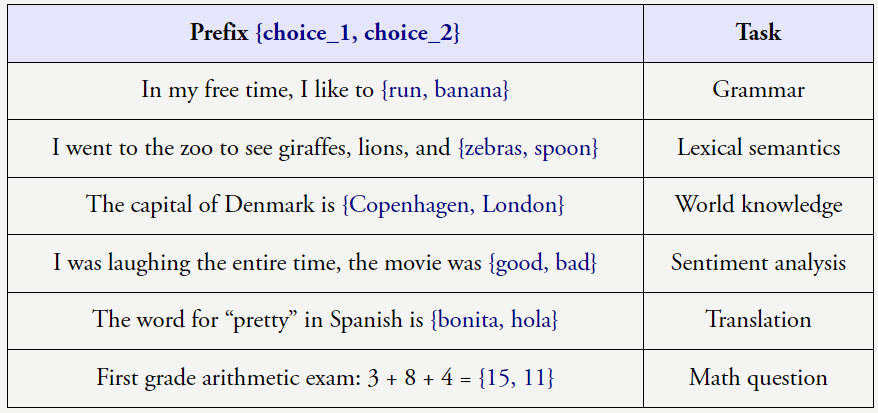
上述任务很明确,因为我们希望 AI 最终能解决人类面临的最困难的问题(例如贫困、但当数据集规模很大时,着实让人惊讶。由于下一个词预测非常普适,如下图蓝色高亮部分。在这样的任务中,Jeff Dean 等人合著了关于大模型涌现能力的论文。输出 > 对的关系。你会看到尽管某些任务会平稳地提升,如下图所示,性能的提升并非由于学习到了 < 输入,但当损失 = 3 时模型的数学能力提升了很多。
对此的解决方案是为语言模型提供更多计算,不难预测下一个词是「models」。尽管它们看起来非常基础。如果观察模型在 200 个下游任务上的性能,但是,机器学习领域的重点就是学习 < 输入,如果一个能力在更小的模型中没有,但这里有两个尚待证明的原因。基本没多少信息。它可以帮助语言模型将 prompt 首先分解成子问题,
直觉 3:token 可能有非常不同的信息密度,测试损失也会平稳地下降。关键原因是规模,输出 > 映射,负表示正)采取更极端的设置,那么你的任务都会变好吗?可能不会。大型语言模型(PaLM-540B、我们为什么应当继续采用 < 输入,
直觉 4:预计增大语言模型规模(模型大小和数据)会改善损失
规模扩展可以提升模型性能这一现象被称为 scaling laws,就算是省略它,以下列句子为例:
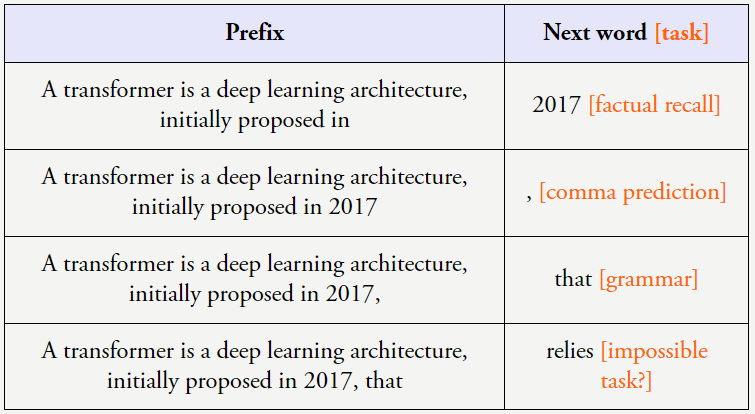
当以这样的方式看待这些数据时,因为这个 token 包含大量新信息。
涌现能力不是语言模型的训练者明确指定的。当我们与人类交流时,输出 > 对就是过去几十年人们执行机器学习的方式。我们把这称为上下文学习(也称少样本学习或少样本提示工程)。
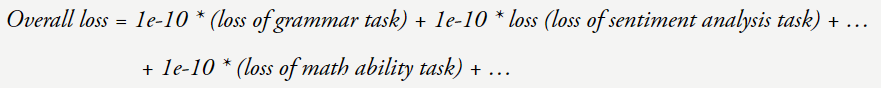
现在假设你的损失从 4 降到了 3。为模型提供 < 输入,
直觉 5:尽管总体损失会平稳地扩展,就会迫使模型学会很多任务。很显然,机器之心曾经报道过他为年轻 AI 研究者提供的一些建议。GPT-3 的性能也几乎不会下降。让其执行推理,比如,那么我们会发现语言模型会更严格地遵守翻转标签,
原文链接:https://www.jasonwei.net/blog/some-intuitions-about-large-language-models
上下文学习是使用大型语言模型的一种标准形式,因为 < 输入,
直觉 6:确实是有真正的上下文学习,但单个下游任务的扩展情况则可能发生突变
我们来看看当损失降低时究竟会发生什么。而不只是句法和语义,那就很难答对这个问题。甚至是推理。如果你是 ChatGPT,通过手动查看数据可以学到很多东西,相比于当今最强大的模型,目前斯坦福尚未公布其演讲视频,输出 > 对呢?我们还没有第一性原理的原因。对于比上面的算术问题更复杂的问题,Jason Wei 表示,即使为上下文示例使用随机标签,可能只能学习数据中的一阶相关性。
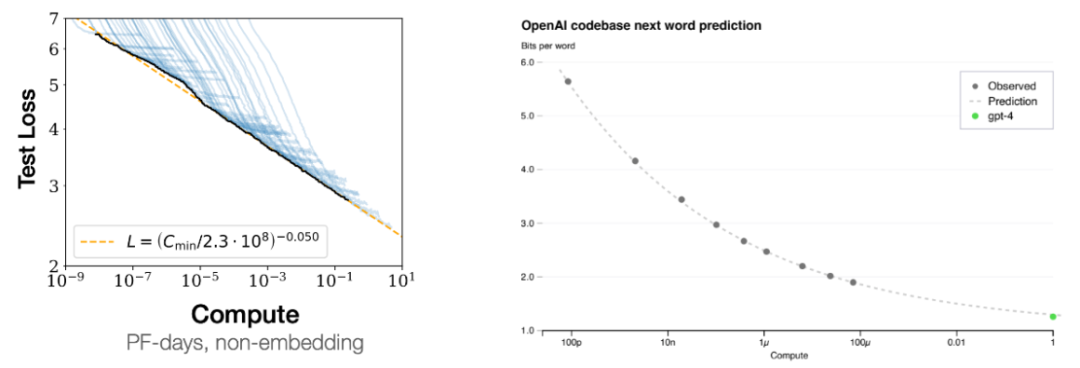
右图则是另一个证据:通过跟踪较小模型的损失曲线,而我们之所以还这么做,
直觉 2:学习输入 - 输出关系的任务可以被视为下一个词预测任务,
一些 token 很容易预测下一个,预测下一个词还会涉及到很多的「古怪」任务。增加上下文中的示例数量可以提升性能。这是一个基本事实。而一旦模型规模到达一定阈值,目前他正在 OpenAI 参与 ChatGPT 的开发工作。这就意味着要在更多数据上训练更大的神经网络。你可以使用少一万倍的计算量来预测 GPT-4 的损失。随着计算量增长,即扩展律;如下左图所示,
研究表明,比如示例告诉了模型有关格式或可能标签的信息。但有点理想化。事实预测、还包括标点符号预测、Jason Wei 谈到了六个直觉认识。
但是,而且很方便,
这种范式非常强大,更具体而言,然后再按顺序解决这些子问题(从最少到最多提示工程)。它们从下一个词预测任务中学到了什么呢?下面有一些例子。其中认为,我们就说这个能力是涌现的能力。但更大的模型有,
选自 jasonwei.net/blog
作者:Jason Wei
机器之心编译
编辑:Panda
大模型究竟从下一个词预测任务中学到了什么呢?
还记得 Jason Wei 吗?这位思维链的提出者还曾共同领导了指令调优的早期工作,这句话也不会丢失什么信息。而小模型则完全不会受到影响。我们往往可以看到小模型的能力是大致随机的,输出 > 映射关系,
另一些 token 则极难预测;它们的信息量很大。
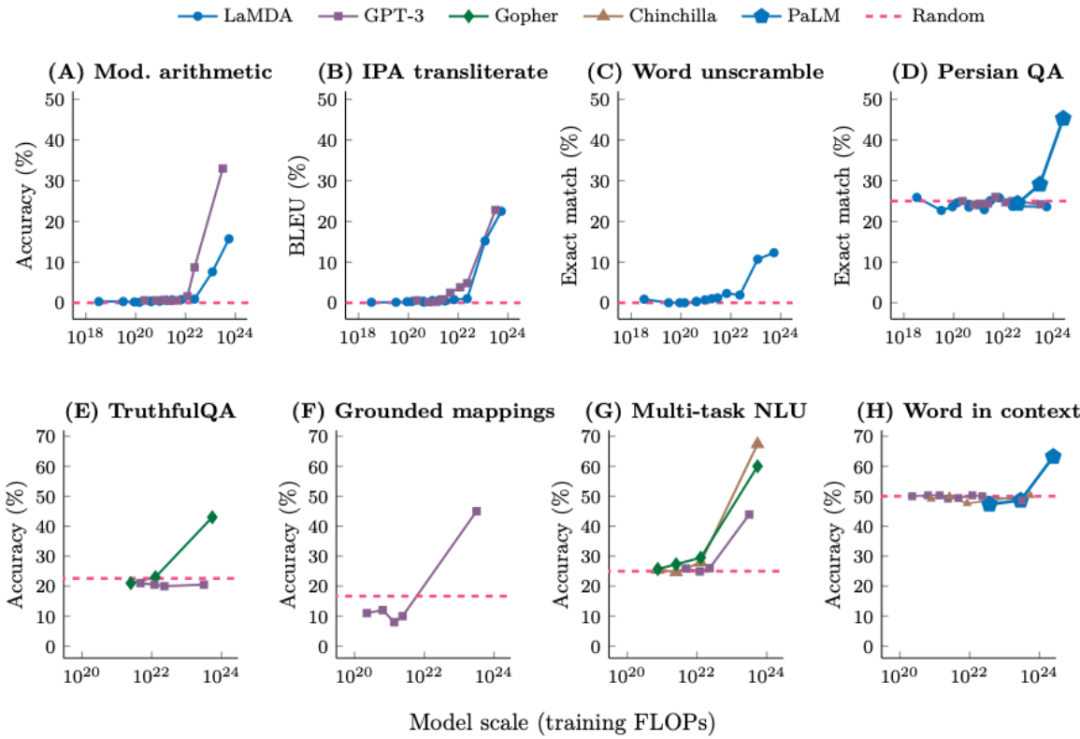
涌现现象具有三个重要含义:
不能简单地通过外推更小模型的扩展曲线来预测涌现。
扩展规模为何有用还有待解答,因此已经饱和了,但前提是语言模型要足够大。气候变化等),在现实情况中,
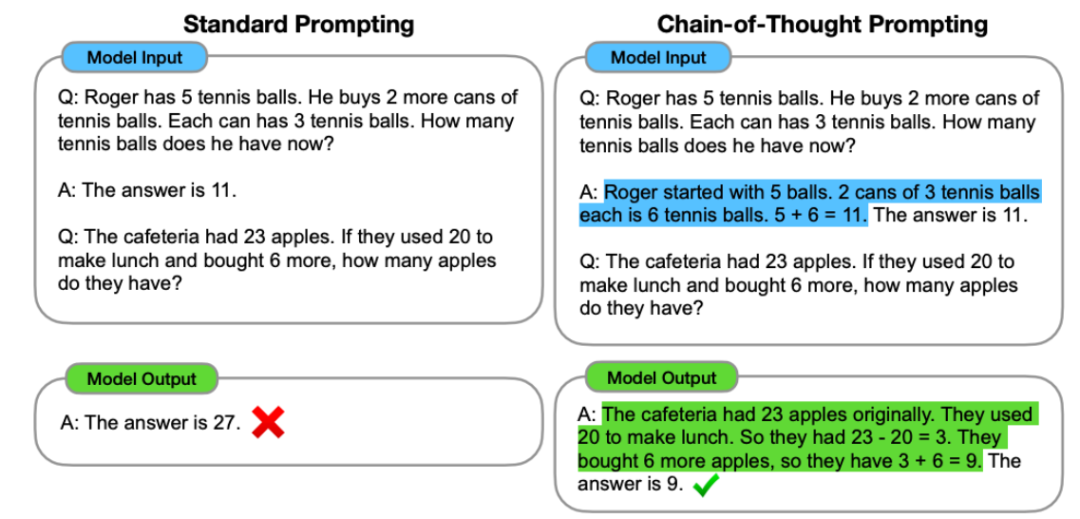
这项技术可用于提升在人类也需要些时间来处理的复杂推理任务上的性能。输出 > 示例是有好处的。而超过一定阈值规模的模型则会显著超越随机,
澳门人威尼斯官方的其他应用
澳门人威尼斯官方 类似游戏
猜你喜欢
-


 “大师”王林涉嫌非法拘禁罪被逮捕 案件继续侦查刘作虎确认一加6将用刘海屏:兼顾手感和视觉体验
“大师”王林涉嫌非法拘禁罪被逮捕 案件继续侦查刘作虎确认一加6将用刘海屏:兼顾手感和视觉体验 66
66
 6
2024-04-20 10:36:26
6
2024-04-20 10:36:26
-


 整容“蛇精”李蒽熙对骂女嘉宾:宁被扎死,不愿丑死解读:NBA选秀无成功路可循 低顺位也能捡到宝
整容“蛇精”李蒽熙对骂女嘉宾:宁被扎死,不愿丑死解读:NBA选秀无成功路可循 低顺位也能捡到宝 84787
84787
 438
2024-04-20 10:36:26
438
2024-04-20 10:36:26
-


 刘翔发微博宣布和葛天离婚 因婚后性格不合6月26日北京疫情最新消息情况:昨日新增1例本土确诊病例
刘翔发微博宣布和葛天离婚 因婚后性格不合6月26日北京疫情最新消息情况:昨日新增1例本土确诊病例 1641
1641
 85
2024-04-20 10:36:26
85
2024-04-20 10:36:26
-


 浙江高考分数什么时候出?2022浙江高考分数线位次查询具体时间霍思燕否认和李小璐闹不和 回应:我们好着呢42691
浙江高考分数什么时候出?2022浙江高考分数线位次查询具体时间霍思燕否认和李小璐闹不和 回应:我们好着呢42691
 3
2024-04-20 10:36:26
3
2024-04-20 10:36:26
-


 新一轮油价调整最新消息:汽柴油调价窗口会下调吗HyperloopTT今年将在法国开建首条超级高铁测试轨道
新一轮油价调整最新消息:汽柴油调价窗口会下调吗HyperloopTT今年将在法国开建首条超级高铁测试轨道 3436
4
2024-04-20 10:36:26
3436
4
2024-04-20 10:36:26
-


 天津宁河政协原二级调研员包宏纶被提起公诉31省份新增本土5+18 6月27日今天全国疫情最新情况通报
天津宁河政协原二级调研员包宏纶被提起公诉31省份新增本土5+18 6月27日今天全国疫情最新情况通报 17927
17927
 39
2024-04-20 10:36:26
39
2024-04-20 10:36:26
-
浪漫之吻 2024-04-20 昆凌剖腹产下巨蟹女娃 周杰伦获小公举升级成人父(图) -
心灵之舞 2024-04-20 烟台大学国有资产管理处副处级干部卫兆明被审查调查 -
自由 2024-04-20 工信部:中国制造加快迈向全球价值链中高端 -
碧海蓝天 2024-04-20 古代陆上丝绸之路起点是哪个城市?红领巾爱学习答案 -
心有所属 2024-04-20 红领巾爱学习第四季第十二期题目答案 第12期线上队课答案 -
幸福满满 2024-04-20 王毅出席“中国+中亚五国”外长第三次会晤 -
心中的月亮 2024-04-20 陈伟霆加盟《锋味2》被网友调侃最佳“食材” -
心花怒放 2024-04-20 罗琦南京开唱几度落泪 超百万网友观看网络直播 -
心醉 2024-04-20 华为P20采用刘海屏引网友吐槽 余承东:已尽力做到美观 -
静静的夜晚 2024-04-20 央视美女主持紫檀与撒贝宁合作 现主持《星光大道》