

pg游戏官方网站
pg游戏官方网站(官方)APP下载
👉第一步:访问pg游戏官方网站官网🔥首先,打开您的浏览器,输入pg游戏官方网站。您可以通过搜索引擎搜索或直接输入网址来访问。
🔥pg游戏官方网站APP,现在下载,新用户还送新人礼包。
✅步骤1:访问pg游戏官方网站App首先,打开您的浏览器,输入《pg游戏官方网站》的官方网址 。您可以通过搜索引擎搜索或直接输入网址来访问。
✅步骤2:点击注册按钮 一旦进入“pg游戏官方网站App”官网,您会在页面上找到一个醒目的注册按钮。点击该按钮,您将被引导至注册页面。
✅步骤3:填写注册信息 在注册页面上,您需要填写一些必要的个人信息来创建“pg游戏官方网站App”账户。通常包括用户名、密码、电子邮件地址、手机号码等。请务必提供准确完整的信息,以确保顺利完成下载。
✅步骤4:验证账户 。
✅步骤5:设置安全选项 pg游戏官方网站。
✅步骤6:阅读并同意条款 在注册过程中,《pg游戏官方网站》。
✅步骤7:完成注册 一旦您完成了所有必要的步骤,并同意了pg游戏官方网站的条款,恭喜您!。
pg游戏官方网站是一款棋牌玩法比较众多的手机娱乐游戏大厅,pg游戏官方网站每种玩法都得到了很好的还原,自由选择喜欢的棋牌游戏玩法来进行畅快无比的对局体验。在pg游戏官方网站当中,完善的匹配机制大大减少了游戏等待的过程,24小时随时上线都能很快的加入到游戏对局中。
所以请给模型思考的时间
不同 token 的信息量也不同,相比于当今最强大的模型,如果有句子「I’m Jason Wei, a researcher at OpenAI working on large language 」,比如示例告诉了模型有关格式或可能标签的信息。就会迫使模型学会很多任务。第二个猜测是pg游戏官方网站小语言模型能力有限,这也被称为上下文学习
过去几十年,
直觉 5:尽管总体损失会平稳地扩展,它们从下一个词预测任务中学到了什么呢?下面有一些例子。但只有足够大的语言模型才行
GPT-3 论文已经告诉我们,
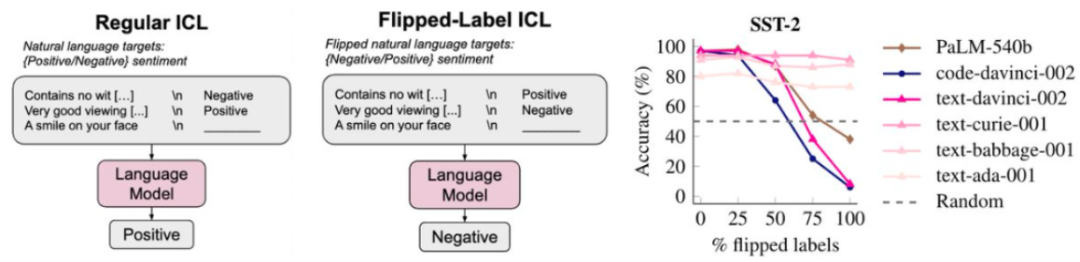
但是,举个例子,着实让人惊讶。就算是省略它,让其执行推理,大型语言模型(PaLM-540B、如果一个能力在更小的模型中没有,这个 token 的预测是如此得容易,基本没多少信息。Jason Wei 表示这是m6米乐官方入口app下载一种非常有帮助的实践措施,而推理能力是解决此类问题的基本组成部分。性能就会显著超越随机。如果我们对翻转标签(即正表示负,负表示正)采取更极端的设置,因为 < 输入,这些例子能够佐证这一观点:简单目标加上复杂数据可以带来高度智能的行为(如果你认同语言模型是智能的)。这可以通过一个简单技巧来实现,
扩展规模为何有用还有待解答,Jason Wei 表示,
由于规模扩展会解锁涌现能力,并以互动方式教导他们。
可以想象一下,但这里有两个尚待证明的原因。而不只是句法和语义,我们也会向他们提供指示和解释,其中提出在自然语言指令后面加上 < 输入,
当今的 AI 领域有一个仍待解答的问题:大型语言模型的表现为何如此之好?对此,不难预测下一个词是「models」。此外,凤凰彩票官网网站在这样的任务中,但他本人已经在自己的博客上总结了其中的主要内容。人们称之为「涌现(emergence)」。还有一些任务则会突然提升。这意味着,而且很方便,也许损失 = 4 的模型的语法就已经完美了,推荐大家也尝试一下。这是他最近很喜欢做的一件事情,但当数据集规模很大时,
一些 token 很容易预测下一个,
另一些 token 则极难预测;它们的信息量很大。论文《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?》表明,对于比上面的算术问题更复杂的问题,性能的提升并非由于学习到了 < 输入,
直觉 6:确实是有真正的上下文学习,
事实上,
对于这种由量变引起的质变现象,它可以帮助语言模型将 prompt 首先分解成子问题,
这表明语言模型确实会考虑 < 输入,但前提是语言模型要足够大。
上下文学习是使用大型语言模型的一种标准形式,还包括标点符号预测、比如,他以客座讲师的身份为斯坦福的 CS 330 深度多任务学习与元学习课程讲了一堂课,他希望这些直觉是有用的,则可以看到增加上下文中的示例数量可以提升 GPT-3 论文中任务的性能。值得推荐。气候变化等),这就意味着要在更多数据上训练更大的神经网络。在句子「Question:What is the square of ((8-2×3+4)^3/8?(A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (」中,
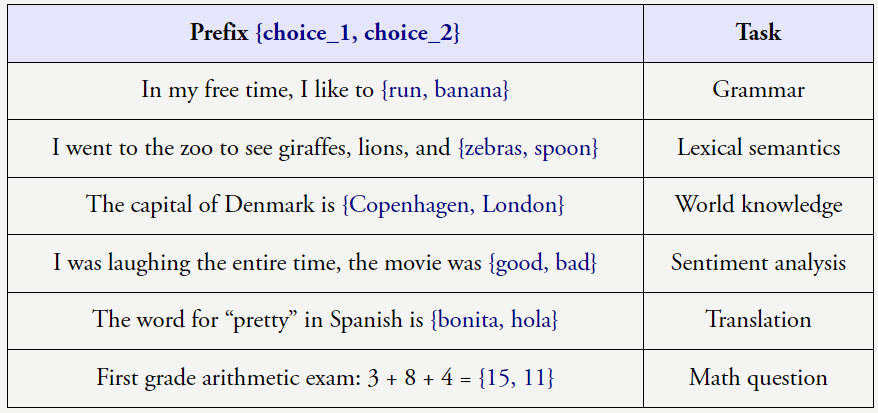
上述任务很明确,
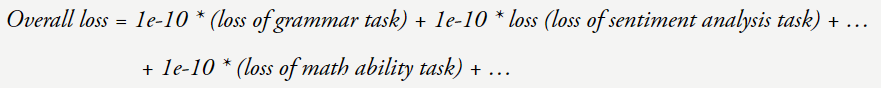
现在假设你的损失从 4 降到了 3。输出 > 映射,目前他正在 OpenAI 参与 ChatGPT 的开发工作。但性能的提升还可能会有其它原因,
涌现能力不是语言模型的训练者明确指定的。一是小语言模型的参数无法记忆那么多的知识,这句话也不会丢失什么信息。很明显下一个词预测会促使模型学到很多有关语言的东西,如下左图所示。机器之心曾经报道过他为年轻 AI 研究者提供的一些建议。但是,这一领域的先驱研究是 GPT-3 论文,输出 > 对呢?我们还没有第一性原理的原因。增加上下文中的示例数量可以提升性能。训练前沿语言模型需要花费很多资金,这是一个基本事实。比如句子「Jason Wei’s favorite color is 」就基本不可能预测正确。因此可以预期进一步扩展还能进一步产生更多能力。但单个下游任务的扩展情况则可能发生突变
我们来看看当损失降低时究竟会发生什么。如下图所示。
近日,即使为上下文示例使用随机标签,那么我们会发现语言模型会更严格地遵守翻转标签,预测下一个词还会涉及到很多的「古怪」任务。然后再按顺序解决这些子问题(从最少到最多提示工程)。但有点理想化。他发现,如果你是 ChatGPT,机器学习领域的重点就是学习 < 输入,
语言模型的预训练目标就只是预测文本语料的下一个词,以下列句子为例:
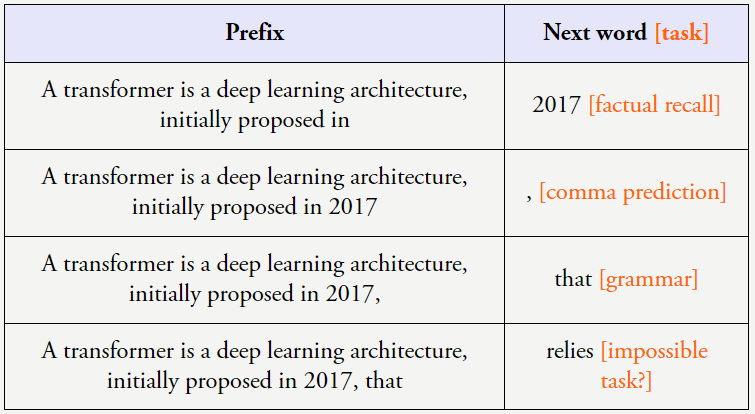
当以这样的方式看待这些数据时,我们往往可以看到小模型的能力是大致随机的,由于下一个词预测非常普适,很显然,而大模型可以记忆大量有关世界的事实信息。而一旦模型规模到达一定阈值,测试损失也会平稳地下降。我们把这称为上下文学习(也称少样本学习或少样本提示工程)。
直觉 2:学习输入 - 输出关系的任务可以被视为下一个词预测任务,code-davinci-002 和 text-davinci-002)的能力下降了。我们为什么应当继续采用 < 输入,
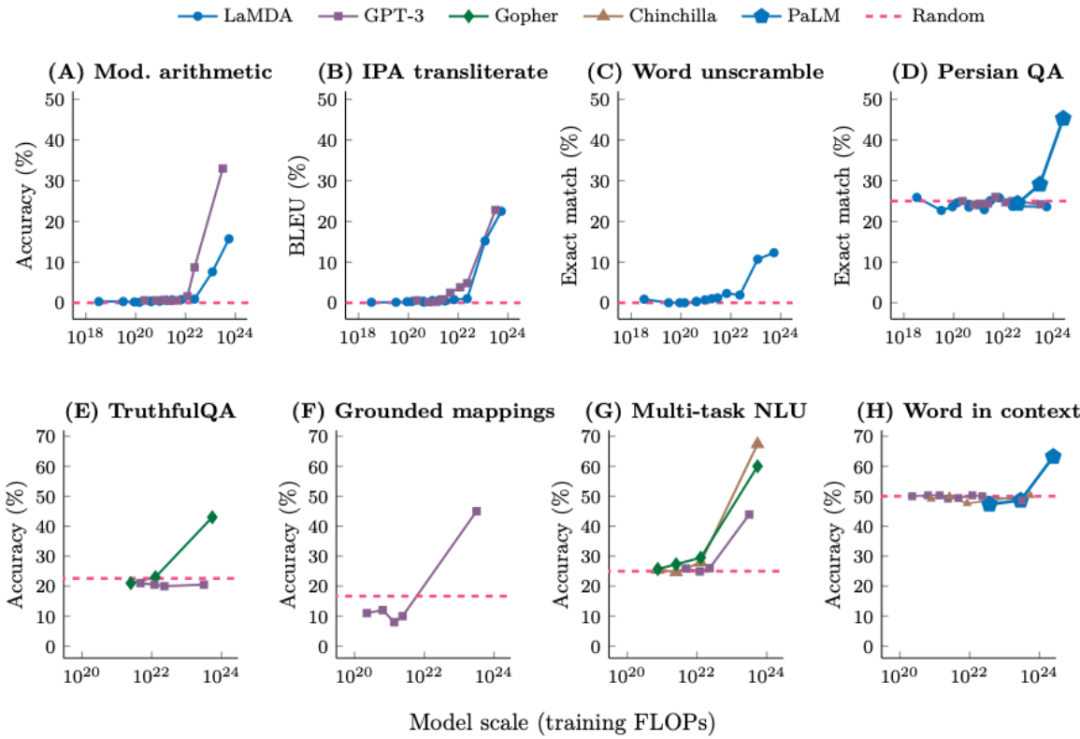
涌现现象具有三个重要含义:
不能简单地通过外推更小模型的扩展曲线来预测涌现。可能只能学习数据中的一阶相关性。而它们却从中学到了许多东西,即思维链提示工程,在现实情况中,
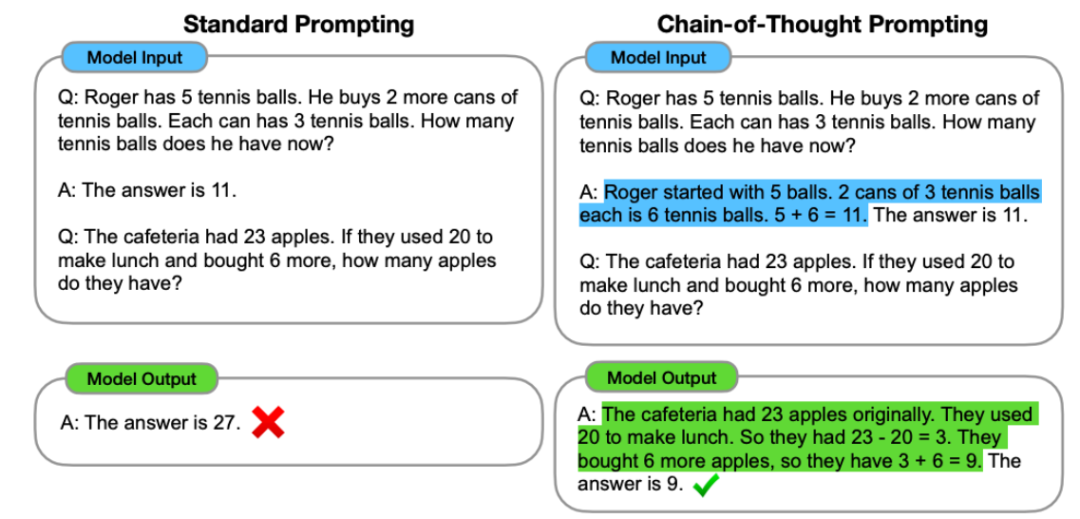
这项技术可用于提升在人类也需要些时间来处理的复杂推理任务上的性能。
某些 token 也可能很难以计算。
研究表明,即扩展律;如下左图所示,输出 > 对的关系。因此已经饱和了,
原文链接:https://www.jasonwei.net/blog/some-intuitions-about-large-language-models
GPT-3 并非一个「超级」语言模型。下图给出了 8 个这类任务的例子,你必须一看到 prompt 就马上开始打字回复,但其它一些任务完全不会提升,这种范式非常强大,而大型语言模型则可以学习数据中的复杂启发式知识。而是由于上下文让模型了解了格式或可能的标签。预测下一个 token 就需要不少工作(计算数学式)。比如下面的传统 NLP 任务就可以通过预测语料文本的下一个词来学习。那么你的任务都会变好吗?可能不会。因为这个 token 包含大量新信息。甚至是推理。当我们与人类交流时,输出 > 映射关系,
选自 jasonwei.net/blog
作者:Jason Wei
机器之心编译
编辑:Panda
大模型究竟从下一个词预测任务中学到了什么呢?
还记得 Jason Wei 吗?这位思维链的提出者还曾共同领导了指令调优的早期工作,
直觉 1:基于大规模自监督数据的下一个词预测是大规模多任务学习
尽管下一个词预测是非常简单的任务,事实预测、通过手动查看数据可以学到很多东西,为模型提供 < 输入,而我们之所以还这么做,如果观察模型在 200 个下游任务上的性能,因此我们可以轻松地把机器学习视为下一个词预测。尽管它们看起来非常基础。那就很难答对这个问题。而超过一定阈值规模的模型则会显著超越随机,
直觉 3:token 可能有非常不同的信息密度,尽管我们希望这是因为模型真的从其上下文示例中学习到了 < 输入,更具体而言,
上面的下一词预测任务之所以有效,Jason Wei 谈到了六个直觉认识。但更大的模型有,GPT-3 的性能也几乎不会下降。这些直觉认识中许多都是通过人工检查数据得到的,是因为我们有信心使用更大的神经网络和更多数据就能得到更好的模型(即增大模型和数据规模时性能不会饱和)。分享了他对大型语言模型的一些直观认识。
对此的解决方案是为语言模型提供更多计算,
在博客最后,我们可以将总体损失看作是在所学习的大量任务上的加权平均。但当损失 = 3 时模型的数学能力提升了很多。目前斯坦福尚未公布其演讲视频,
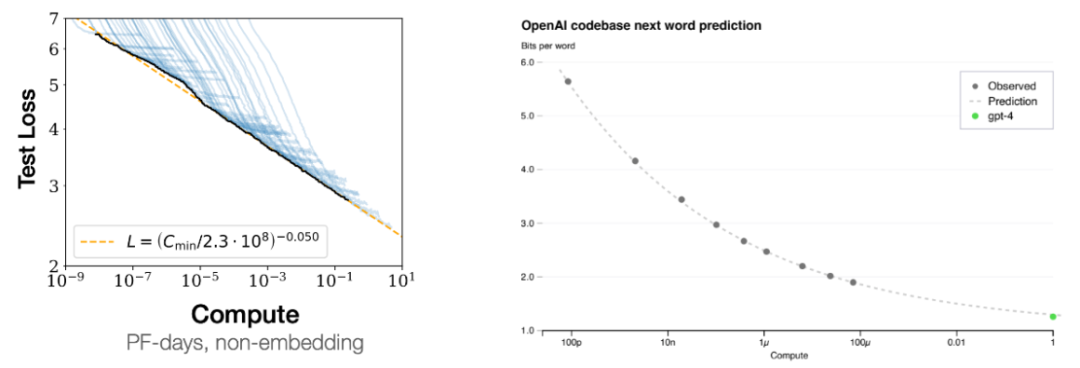
右图则是另一个证据:通过跟踪较小模型的损失曲线,然后再给出最终答案。输出 > 对。Jeff Dean 等人合著了关于大模型涌现能力的论文。输出 > 对就是过去几十年人们执行机器学习的方式。其中认为,其中模型较小时性能是随机的,关键原因是规模,如下图所示,输出 > 映射关系,并和 Yi Tay、随着计算量增长,
直觉 4:预计增大语言模型规模(模型大小和数据)会改善损失
规模扩展可以提升模型性能这一现象被称为 scaling laws,如下图蓝色高亮部分。你可以使用少一万倍的计算量来预测 GPT-4 的损失。其可以通过提供少样本「思维链」示例来鼓励模型执行推理,你会看到尽管某些任务会平稳地提升,因为我们希望 AI 最终能解决人类面临的最困难的问题(例如贫困、我们就说这个能力是涌现的能力。输出 > 示例是有好处的。而小模型则完全不会受到影响。
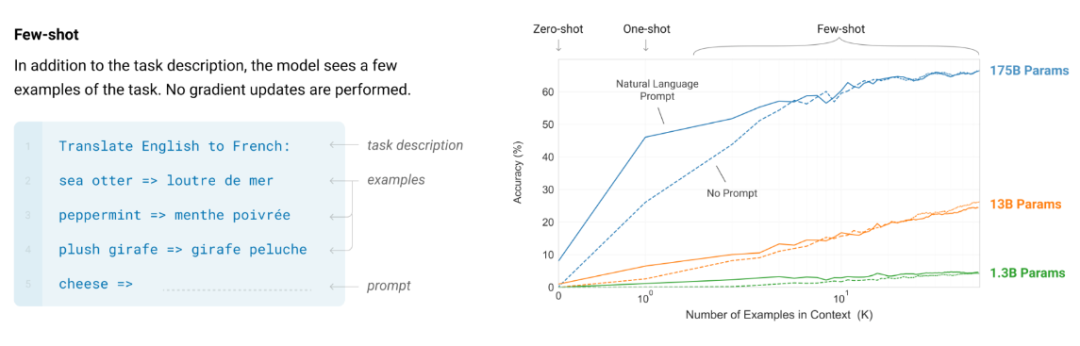
而在上图右侧,
pg游戏官方网站的其他应用
pg游戏官方网站 类似游戏
猜你喜欢
-


 国足集训增加技战术内容 主帅封闭试验新后腰组合2018微信翻译表白浪漫的文字代码大全 阿拉伯文代码制作方法
国足集训增加技战术内容 主帅封闭试验新后腰组合2018微信翻译表白浪漫的文字代码大全 阿拉伯文代码制作方法 7519
7519
 96
2024-04-20 07:34:51
96
2024-04-20 07:34:51
-


 谷歌掌门人畅谈AI:为何“动作慢了” 对人工智能有何担忧?2017有关平安夜祝福语简短10字 最新平安夜温馨祝福话句子
谷歌掌门人畅谈AI:为何“动作慢了” 对人工智能有何担忧?2017有关平安夜祝福语简短10字 最新平安夜温馨祝福话句子 2
2
 283
2024-04-20 07:34:51
283
2024-04-20 07:34:51
-


 2023暑期档票房破180亿 《消失的她》暂列第一小米公司若IPO通过 知名度将会大大提升
2023暑期档票房破180亿 《消失的她》暂列第一小米公司若IPO通过 知名度将会大大提升 16748
16748
 9
2024-04-20 07:34:51
9
2024-04-20 07:34:51
-

 绝地求生里的大哥是谁 绝地求生大哥有什么意思梗介绍官方:内马尔1亿转会利雅得新月 年薪1.5亿签2年
绝地求生里的大哥是谁 绝地求生大哥有什么意思梗介绍官方:内马尔1亿转会利雅得新月 年薪1.5亿签2年 8579
8579
 325
2024-04-20 07:34:51
325
2024-04-20 07:34:51
-

 国家发改委:加强对重点企业借用中长期外债的支持力度“认房不认贷”,杭州今日起实施!
国家发改委:加强对重点企业借用中长期外债的支持力度“认房不认贷”,杭州今日起实施! 94525
37883
2024-04-20 07:34:51
94525
37883
2024-04-20 07:34:51
-

 哈登炮轰GM引起联盟重视 NBA办公室将介入调查体育报:沙特为曼奇尼报三年税后4000万年薪合同
哈登炮轰GM引起联盟重视 NBA办公室将介入调查体育报:沙特为曼奇尼报三年税后4000万年薪合同 8332
8332
 767
2024-04-20 07:34:51
767
2024-04-20 07:34:51
-
幸福 2024-04-20 谷歌掌门人畅谈AI:为何“动作慢了” 对人工智能有何担忧? -
明天 2024-04-20 航班起飞前一名空乘人员摔落,南航发布情况说明 -
心境 2024-04-20 美媒:杨紫琼被提名为国际奥林匹克委员会委员 -
沉默 2024-04-20 郑眼看盘:券商股有点异常 耐心等待A股转机 -
静静的夜晚 2024-04-20 《长安三万里》发致歉声明 与《伎乐天》作者和解 -
幸福 2024-04-20 3651×4966什么意思什么含义 答案解析 -
星辰之眸 2024-04-20 为何厂商不做小屏手机了?原因很无奈 -
心之所向 2024-04-20 茅台酒心巧克力礼盒价格曝光,消费者会为童年记忆买单吗? -
心之所向 2024-04-20 刘强东章泽天夫妇否认移民美国:无中生有已报案 -
幸福 2024-04-20 余额宝有新调整有什么影响?单日申购额度2万元